hadoop组成
hadoop1.x
- Common 辅助工具
- HDFS 数据存储
- MapReduce
- 计算
- 资源调度
hadoop2.x
- Common 辅助工具
- HDFS 数据存储
- MapReduce (计算)
- Yarn (资源调度)
hadoop3.x在组成上和hadoop2.x没有区别
HDFS概述
HDFS:Hadoop Distributed File System 是一个分布式文件系统
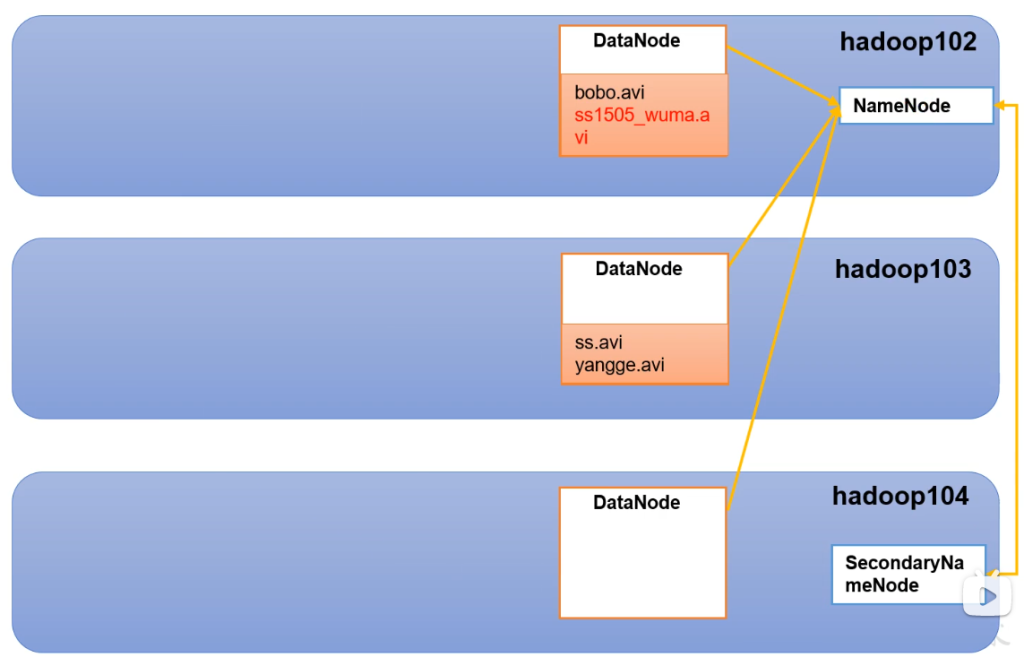
- NameNode (nn)
- 存储文件的元数据
- 文件名
- 文件目录结构
- 文件属性(生成时间、副本数、文件权限)
- 每个文件的块列表和块所在的DataNode等
- 存储文件的元数据
- DataNode(dn)
- 在本地文件系统存储文件块数据,以及块数据的校验和
- Secondary Name Node (2nn) 每隔一段时间对NameNode元数据备份
Yarn 架构概述
Yet Another Resource Negotiator 另一种资源协调者
是hadoop的资源管理器
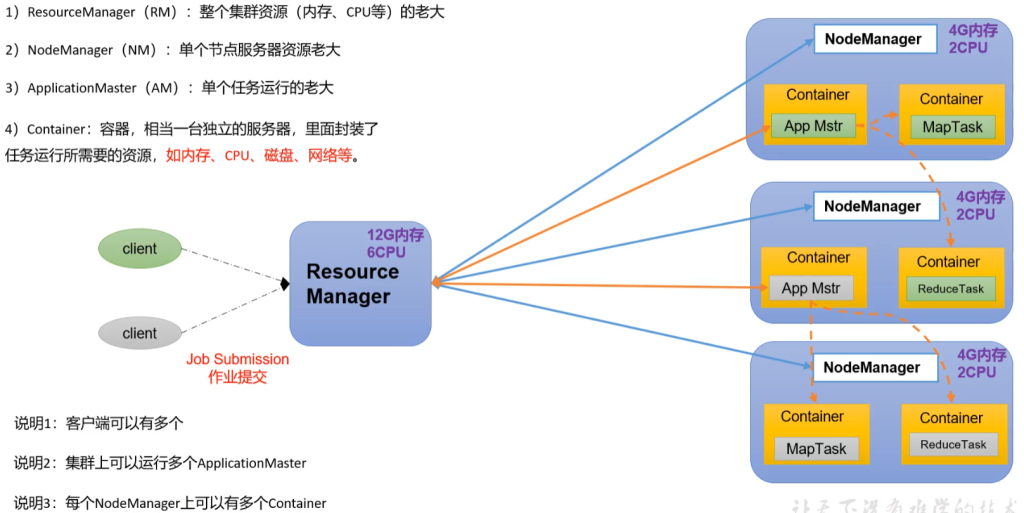
- ResourceManager (RM) 整个集群资源(内存、cpu)的老大
- NodeManager (NM) 单个节点服务器资源老大
- ApplicationMaster (AM) 单个任务运行的老大
- 客户端提交任务 RM 找一台节点 开启一个Container 然后放入任务AM
- 运行任务时向RM申请资源
- RM安排在某个节点上开辟Container并在其中运行任务
- 运行资源不够RM再分配一个节点开辟Container并在其中运行任务
- 集群上可以运行多个ApplicationMaster
- Container 容器,相当一台独立的服务器,里面封装了任务运行所需的资源,如内存、CPU、磁盘、网络等
- 每个NodeManger上可以有多个Container
- 一个Container默认1-8G
MapReduce架构概述
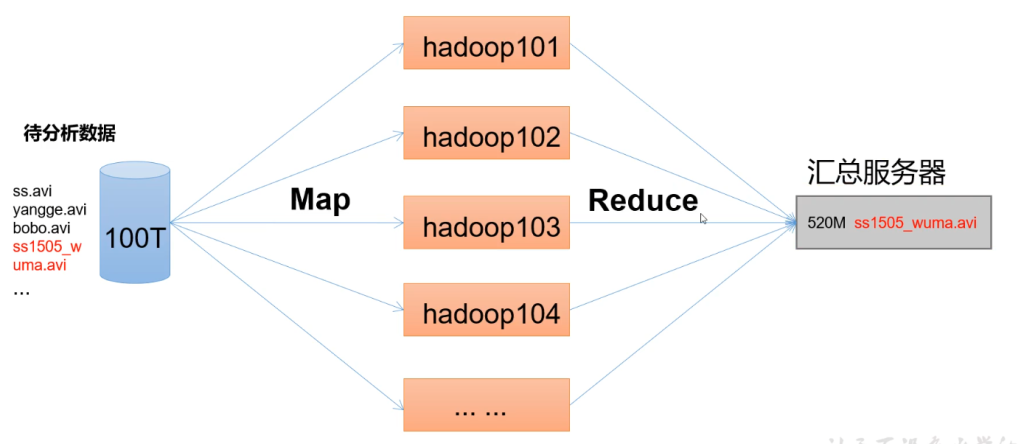
mapreduce将计算过程分为两个阶段:Map和Reduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
HDFS YARN MAPREDUCE三者关系
hdfs
hdfs yarn
hdfs yarn 任务
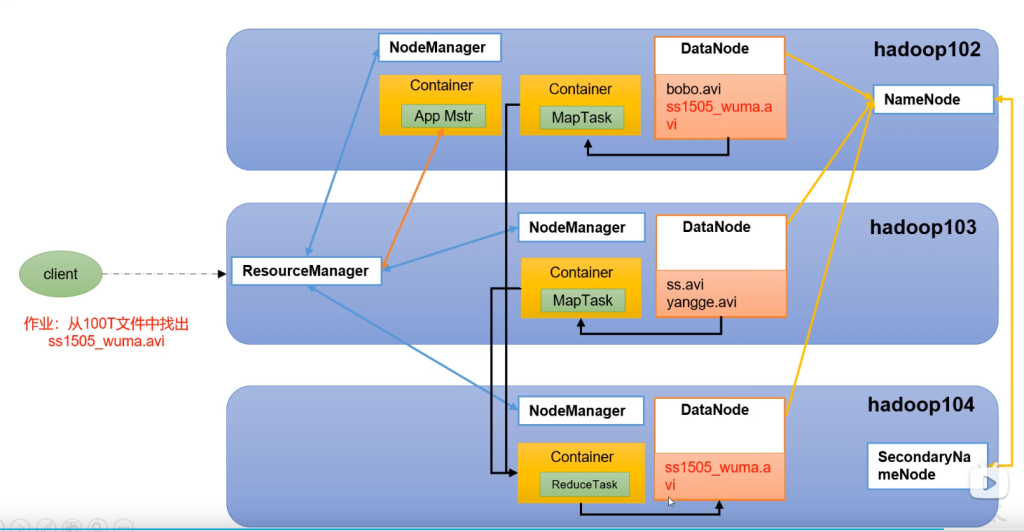
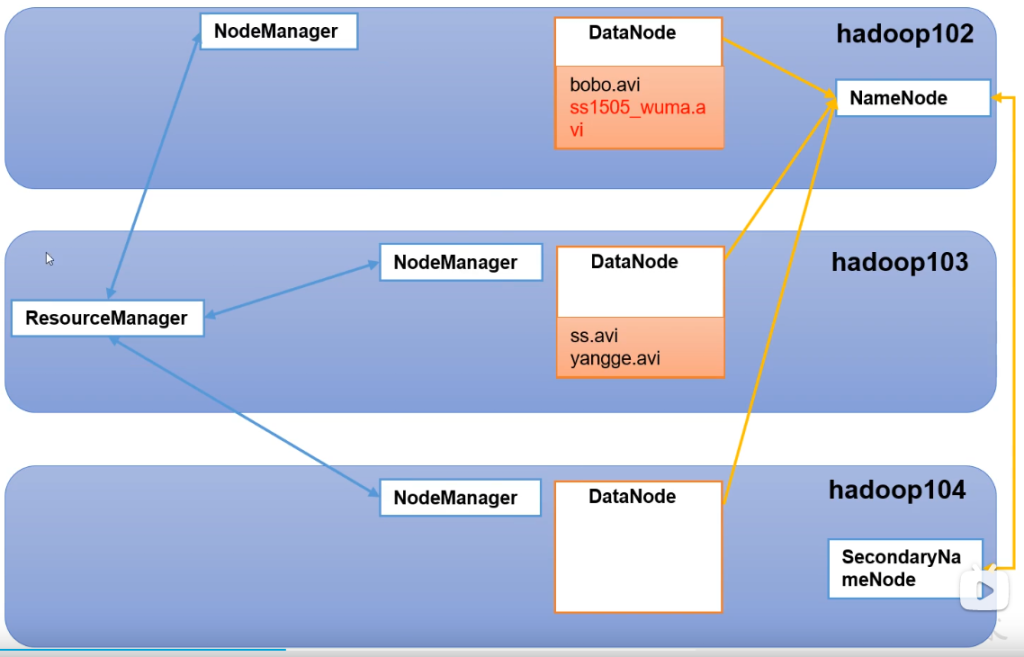
- 用户提交任务
- RM从其中一个节点上开启一个Container存放任务AM
- AM向RM申请资源用于MapReduce
- RM分配其中几个节点开启Container,执行MapTask
- 最后另一个节点将结果Reduce并保存到DataNode中
- NameNode记录存储DataNode信息
- 2NN备份NN一份记录
大数据生态体系
- 数据来源层
- 结构化数据
- 数据库
- 半结构化数据
- 文件日志
- 非结构化数据
- 视频
- ppt等
- 结构化数据
- 消息传输层
- sqoop数据传递
- flume日志收集
- kafka消息队列
- 数据存储层
- HDFS文件存储
- HBase非关系型数据库
- kafka消息队列
- 资源调度
- YARN资源管理
- 数据计算层
- MapReduce离线计算
- Hive数据查询
- Spark Core内存计算
- Spark Sql 数据查询
- Spark Mlib 数据挖掘
- Spark Streaming 实时计算
- Storm实时计算
- Flink
- MapReduce离线计算
- 任务调度层
- Ooozie
- Azkaban
- 数据平台配置和调度
- zookeeper
- 业务模型层
- 业务模型
- 数据可视化
- 业务应用