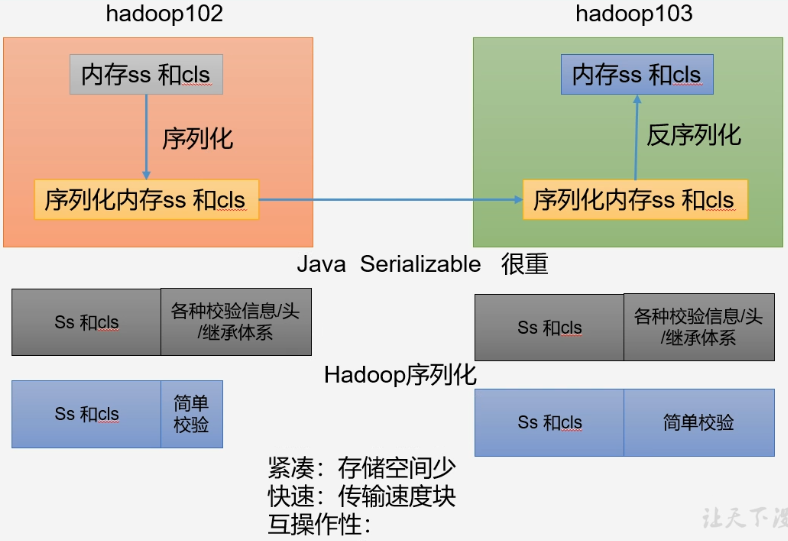
- 序列化就是把内存中的对象转换成字节序列(或其他数据传输协议),以便存储到磁盘(持久化)和网络传输
- 反序列化就是将收到的字节序列或者是磁盘的持久化数据转换成内存中的对象
自定义bean对象实现序列化接口(Writeable)
实现bean对象序列化步骤:
- 必须实现Writeable
- 反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean() {
super();
}重写序列化方法
@override
public void write(DataOutput out) throws IOException {
// 以下数据逐个发送
// 上行流量
out.writeLong(upFlow);
// 下行流量
out.writeLong(downFlow);
// 总流量
out.writeLong(sumFlow);
}重写反序列化方法
@override
public void readFields(DataInput in) throws IOException {
// 接收数据反序列化顺序必须和序列化顺序一致
upFlow = in.readLong();
downF = in.readLong();
sumFlow = in.readLong();
}- 注意反序列化的顺序和序列化的顺序完全一致
- 想要把结果显示在文件中,需要重写toString()用\t分开,方便后续使用
- 如果需要自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框架中Shuffle过程要求对key必须能排序
@override
public int compareTo(FlowBean o) {
// 倒序排序,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}序列化案例

FlowBean.java
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1.定义类实现writeable接口
* 2.重写序列化和反序列化方法
* 3.重写空参构造
* 4.toString方法
*/
public class FlowBean implements Writable {
private long upFlow; // 上行流量
private long downFlow; // 下行流量
private long sumFlow; // 总流量
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
// 重写空参构造
public FlowBean() {
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
}FlowMapper.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
private final FlowBean outV = new FlowBean();
private final Text outK = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取一行数据
String line = value.toString();
// 切割数据
String[] split = line.split("\t");
// 获取手机号
String phone = split[1];
// 获取上下行流量
String up = split[split.length - 3];
String down = split[split.length - 2];
// 封装
outV.setUpFlow(Long.parseLong(up));
outV.setDownFlow(Long.parseLong(down));
outV.setSumFlow();
outK.set(phone);
context.write(outK, outV);
}
}FlowReducer.java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
private final FlowBean outV = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
// 遍历集合累加值
long totalUp = 0;
long totalDown = 0;
for (FlowBean value : values) {
totalUp += value.getUpFlow();
totalDown += value.getDownFlow();
}
// 封装outV
outV.setUpFlow(totalUp);
outV.setDownFlow(totalDown);
outV.setSumFlow();
// 写出
context.write(key, outV);
}
}FlowDriver.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.设置jar
job.setJarByClass(FlowDriver.class);
// 3.关联mapper 和 reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 4.设置mapper输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 5.设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 6.设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("E:\\hadoop\\input"));
FileOutputFormat.setOutputPath(job, new Path("E:\\hadoop\\output1"));
// 7.提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}