除了检查点,flink还提供了另一个非常独特的镜像保存功能:保存点(savepoint)
这也时一个存盘的备份,原理和算法与检查点完全相同,只是多了一些额外的元数据
保存点的用途
保存点与检查点最大的区别,就是触发的时机。
- 检查点时由Flink自动管理的,定期创建,发生故障之后自动读取进行恢复,这时一个自动存盘的功能
- 保存点不会自动创建,必须由用户明确的手动触发保存操作,所以就是手动存盘
保存点可以当作一个强大的运维工具来使用。我们可以在需要的时候创建一个保存点,然后停止应用,做一些处理调整后再从保存点重启。
适用场景:
- 版本管理和归档存储
- 更新flink版本
- 更新应用程序
- 调整并行度
- 暂停应用程序
需要注意,保存点能够在程序中更改的时候依然兼容,前提时状态的拓扑结构和数据类型不变。
保存点中状态都是以算子ID-状态名称这样的key-value组织起来的,算子ID可以在代码中直接调用.uid()方法来进行指定。
对于没有设置ID的算子,Flink默认会自动进行设置,所以在重新启动医用后可能会导致ID不同而无法兼容以前的状态,所以为了方便后续的维护,强烈建议在程序中为每一个算子手动指定ID。
使用保存点
(1)创建保存点
要在命令行中为运行的作业创建一个保存点镜像:
bin/flink savepoint jobID target_dirtarget_dir可选
对于保存点默认路径,可以通过配置文件flink-conf.yaml中的state.savepoints.dir来指定
state.savepoints.dir: hdfs:///flink/savepoints当然对于单独的作业,我们也可以在程序中设置
env.setDefaultSavepointDir("hdfs:///flink/savepoints")停止作业并创建保存点
bin/flink stop --savepointPath target_dir jobID(2)从保存点重启应用
bin/flink run -s savepointPath 其他参数- 只需要增加一个-s参数指定保存点路径就可以了
- 如果是yarn的运行模式还需要加上 -yid application-id
使用保存点切换状态后端
使用savepoint恢复状态的时候,也可以更换状态后端,但是又一点需要注意的是,不要再代码中指定状态后端了,通过配置文件或者-D参数配置
bin/flink run-application -d -t yarn-application -Dstate.backend=hashmap -c xxx.xxx abc.jar
bin/flink run-application -d -t yarn-application -Dstate.backend=rocksdb -c xxx.xxx abc.jar测试
算子指定uid,name
package com.learn.flink.checkpoint;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class SavepointDemo {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 代码中用到hdfs,需要导入hadoop依赖 指定访问hdfs的用户名
System.setProperty("HADOOP_USER_NAME", "root");
// TODO 检查点配置
// 1、启用检查点,默认是barrier对其的,周期为5s,精准一次
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// 2、指定检查点的存储位置
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
// 使用hdfs需要导入hadoop-client依赖,不建议打包的时间将hadoop依赖打包scope设置provided即可
checkpointConfig.setCheckpointStorage("hdfs://hadoop001:8020/chk");
// 3、checkpoint的超时时间:默认10分钟
checkpointConfig.setCheckpointTimeout(60 * 1000L);
// 4、同时运行中的checkpoint的最大数量
checkpointConfig.setMaxConcurrentCheckpoints(1);
// 5、最小等待间隔:上一轮checkpoint结束 到下一轮 checkpoint开始之间的间隔,设置了大于0,并发就会变成1
checkpointConfig.setMinPauseBetweenCheckpoints(1000L);
// 6、取消作业时,checkpoint是否保留在外部系统
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 7、允许checkpoint连续失败的次数,默认0,表示checkpoint一失败job就挂掉
checkpointConfig.setTolerableCheckpointFailureNumber(3);
// 开启非对其检查点(barrier非对其)
// 开启要求: checkpoint模式必须时精准一次,最大并发必须设为1
checkpointConfig.enableUnalignedCheckpoints();
// 开启非对齐检查点才生效:默认0,表示一开始就直接用 非对齐检查点
// 如果大于0,一开始用 对齐检查点(barrier对齐),对齐的时间超过这个参数,自动切换成 非对齐检查点(barrier非对齐)
checkpointConfig.setAlignedCheckpointTimeout(Duration.ofSeconds(1));
env.socketTextStream("hadoop003", 7777).uid("socket")
.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}).uid("flatmap-wc").name("wc-flatmap")
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(value -> value.f0)
.sum(1).uid("sum-wc")
.print().uid("print-wc");
env.execute();
}
}打包项目 并上传到服务器
提交作业
/data/flink-1.17.1/bin/flink run-application -d -t yarn-application -c com.learn.flink.checkpoint.SavepointDemo ./FlinkLearn1.17-1.0-SNAPSHOT.jar停止flink作业时,触发保存点
# stop 优雅停止 要求source实现StoppableFunction接口
bin/flink stop -p hdfs://hadoop001:8020:/sp job-id -yid application-id
# cancel立即停止
bin/flink cancel -s hdfs://hadoop001:8020/sp job-id -yid application-id# 案例中source是socket不能stop
/data/flink-1.17.1/bin/flink cancel -s hdfs://hadoop001:8020/sp d28fda4f779d876e7131e51c0c7bbcd4 -yid application_1686398277825_2912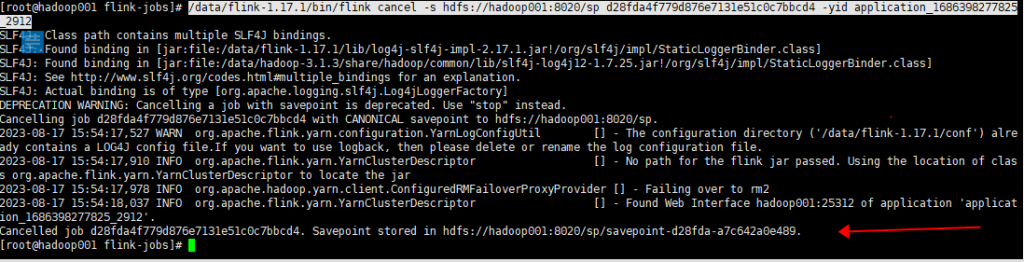
从savepoint恢复作业,同时修改状态后端
/data/flink-1.17.1/bin/flink run-application -d -t yarn-application -s hdfs://hadoop001:8020/sp/savepoint-d28fda-a7c642a0e489 -Dstate.backend=rocksdb -c com.learn.flink.checkpoint.SavepointDemo ./FlinkLearn1.17-1.0-SNAPSHOT.jar没有做savepoint也可以从checkpoint恢复,需要具体到chk-xxx
- 使用checkpoint恢复不能切换状态后端