运行模式
本地运行模式
Local模式:不需要其他任何节点资源就可以在本地执行spark代码的环境
- 解压缩文件,并重命名文件夹为spark-local
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-local启动Local环境
bin/spark-shell命令行工具
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect退出命令行
:quit- 提交应用
- class 表示要执行程序的主类,此处填写自己的应用程序
- master local[2] 部署模式为本地模式 数字表示分配的虚拟CPU核数量
- spark-examples_2.12-3.0.0.jar 运行的–class类所在的jar包,也就是自己的jar包
- 数字10 表示程序的入口参数,用于设定当前应用的任务数量
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10独立运行模式
Standalone模式:使用Spark自身节点运行的集群模式,体现了节点的master-slave模式
| linux1 | linux2 | linux3 | |
| Spark | Worker Master | Worker | Worker |
- 解压缩文件,并重命名文件夹为spark-standalone
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone修改slaves.template文件名为slaves
mv conf/slaves.template slaves修改slaves文件,添加work节点
hadoop001
hadoop002
hadoop003修改spark-env.sh.template文件名为spark-env.sh
mv conf/spakr-env.sh.template spark-env.sh修改spark-env.sh文件添加JAVA_HOME环境变量和集群对应的master节点
export JAVA_HOME=/opt/module/jdk1.8
SPARK_MASTER_HOST=hadoop001
SPARK_MASTER_PORT=7077注意:7077端口相当于hadoop3内部通信的8020端口,此处的端口需要确认自己的Hadoop配置
- 分发spark-standalone目录
xsync spark-standalone启动集群
sbin/start-all.sh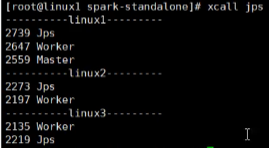
- 查看Master资源监控web ui 界面
- 提交应用
- master spark://hadoop001:7077 独立部署模式连接到spark集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop001:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10提交参数说明
| 参数 | 解释 | 可选值举例 |
| –class | Spark程序中包含主函数的类 | |
| –master | Spark程序运行的模式(环境) | Local[*]、spark://hadoop001:7077、Yarn |
| –executor-memory 1G | 指定每个excutor可用内存位1G | |
| –total-executor-cores 2 | 指定所有excutor使用的cpu核数为2个 | |
| –executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用jar,包含依赖,这个URL在集群中全局可见,比如hdfs:// ,如果是file:// 那么所有节点path都必须包含同样的jar | |
| application-arguments | 传给main()方法的参数 |
配置历史服务
由于spark-shell停止后集群hadoop001:4040页面就看不到历史任务的运行情况,所以需要配置历史服务器记录任务运行情况
- 修改spark-defaults.conf.template文件名为spark-defaults.conf
- 修改spark-default.conf文件,配置日志存储路径
- 需要启动spark集群,hdfs上的logdir目录需要提前存在
- sbin/start-dfs.sh
- hadoop fs -mkdir /logdir
- 需要启动spark集群,hdfs上的logdir目录需要提前存在
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop001:8020/logdir修改spark-env.sh文件,添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop001:8020/logdir
-Dspark.history.retainedApplications=30"- 参数说明:
- 参数1含义:WEB UI访问端口号为18080
- 参数2函数:指定历史服务器日志存储路径
- 参数3含义:指定保存Application历史记录的个数,如果超过这个值,就得应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
- 分发配置文件
xsync conf重新启动集群和历史服务
sbin/start-all.sh
sbin/start-history-server.sh- 重新执行任务即可
配置高可用(HA)
一个master节点可能会单点故障,配置多个Master节点,发生故障时由备用Master提供服务,这里高可用一般采用zookeeper设置
| linux1 | linux2 | linux3 | |
| Spark | Worker Masterzookeeper | Worker Masterzookeeper | Workerzookeeper |
- 停止集群
sbin/stop-all.sh- 启动zookeeper
- 修改spark-env.sh文件添加如下配置
# 注释如下内容
# SPARK_MASTER_HOST = hadoop001
# SPARK_MASTER_PORT = 7077
# 添加如下内容
# Master监控页默认访问端口为8080但是可能会和zookeeper冲突,所以改成8989,也可以自定义
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop001,hadoop002,hadoop003
-Dspark.history.retainedApplications=30"分发配置文件
xsync conf启动集群
sbin/start-all.sh启动hadoop002的单独Master节点,此时hadoop002节点Master处于备用状态
sbin/start-master.sh提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop001:7077,hadoop002:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10- 停止hadoop1的master hadoop002的master将激活ALIVE
Yarn模式
- 解压缩文件,并重命名文件夹为spark-yarn
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn修改hadoop配置文件/opt/module/hadoop/etc/yarn-site.xml并分发
<!-- 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉 默认是true-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否启动一个线程检查每个人物正在使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉 默认是true-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>修改conf/spark-env.sh,添加JAVA_HOME和YARN_CONF_DIR配置
mv spark-env.sh.template spark-env.sh
...start
export JAVA_HOME=/opt/module/jdk1.8
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop- 启动hdfs以及yarn集群
- 提交任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10- 查看yarn历史页面hadoop002:8088
配置Yarn关联Spark历史服务器
- 修改spark-defaults.conf.template文件名为spark-defaults.conf
- 修改spark-default.conf文件,配置日志存储路径
- 需要启动spark集群,hdfs上的logdir目录需要提前存在
- sbin/start-dfs.sh
- hadoop fs -mkdir /logdir
- 需要启动spark集群,hdfs上的logdir目录需要提前存在
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop001:8020/logdir修改spark-env.sh文件,添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop001:8020/logdir
-Dspark.history.retainedApplications=30"- 参数说明
- 参数1含义:WEB UI访问端口号为18080
- 参数2函数:指定历史服务器日志存储路径
- 参数3含义:指定保存Application历史记录的个数,如果超过这个值,就得应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
- 修改spark-defaults.conf
spark.yarn.historySevrer.address=hadoop001:18080
spark.history.ui.port=18080启动历史服务器
sbin/start-history-server.sh重新执行任务即可
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10- 查看日志hadoop002:8088
部署模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master及Worker | Spark | 单独测试部署 |
| Yarn | 1 | Yarn及HDFS | Hadoop | 混合部署 |
端口号
- spark查看当前spark-shell运行任务情况端口号:4044(计算)
- spark master内部通讯服务端口号:7077
- standalone模式下spark master web服务端口号:8080(资源)
- spark历史服务器端口号:18080
- hadoop yarn任务运行情况查看端口号:8088