Blog
高可用大数据集群安装教程
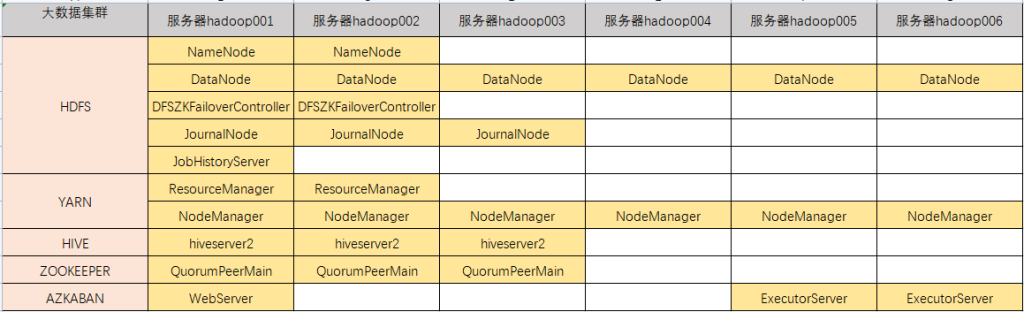
服务器配置
软件存放路径:/opt/software/
程序运行路径:/data/
程序和数据分离:
mkdir -p /data/datas
mkdir -p /data/logs
mkdir -p /data/pids集群分发脚本xsync
依赖:yum install -y rsync
新建文件/root/bin/xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop001 hadoop002 hadoop003
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done赋予执行权限
chmod +x xsync节点进程查看脚本
新建文件/root/bin/xcall.sh
#! /bin/bash
for i in hadoop001 hadoop002 hadoop003
do
echo --------- $i ----------
ssh $i "$*"
done赋予执行权限
chmod +x xcall.shSSH免密登录
1、hadoop001上生成公钥和私钥
[root@hadoop001 .ssh]$ ssh-keygen -t rsa然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
2、将hadoop001公钥拷贝到要免密登录的目标机器上
[root@hadoop001 .ssh]$ ssh-copy-id hadoop001
[root@hadoop001 .ssh]$ ssh-copy-id hadoop002
[root@hadoop001 .ssh]$ ssh-copy-id hadoop003
[root@hadoop001 .ssh]$ ssh-copy-id hadoop004
[root@hadoop001 .ssh]$ ssh-copy-id hadoop005
[root@hadoop001 .ssh]$ ssh-copy-id hadoop0063、hadoop002上生成公钥和私钥
[root@hadoop002 .ssh]$ ssh-keygen -t rsa然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
4、将hadoop002公钥拷贝到要免密登录的目标机器上
[root@hadoop002 .ssh]$ ssh-copy-id hadoop001
[root@hadoop002 .ssh]$ ssh-copy-id hadoop002
[root@hadoop002 .ssh]$ ssh-copy-id hadoop003
[root@hadoop002 .ssh]$ ssh-copy-id hadoop004
[root@hadoop002 .ssh]$ ssh-copy-id hadoop005
[root@hadoop002 .ssh]$ ssh-copy-id hadoop006JDK安装
1、卸载现有JDK
[root@hadoop001 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[root@hadoop002 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[root@hadoop003 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps(1)rpm -qa:表示查询所有已经安装的软件包
(2)grep -i:表示过滤时不区分大小写
(3)xargs -n1:表示一次获取上次执行结果的一个值
(4)rpm -e --nodeps:表示卸载软件
2、上传JDK压缩包到hadoop001:/opt/software目录下
3、解压JDK到/data目录下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /data4、配置JDK环境变量
# 新建/etc/profile.d/my_env.sh文件
[root@hadoop001 data]# sudo vim /etc/profile.d/my_env.sh
# 添加如下内容,然后保存(:wq)退出
#JAVA_HOME
export JAVA_HOME=/data/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
# 让环境变量生效
[root@hadoop001 software]$ source /etc/profile.d/my_env.sh
# 测试JDK是否安装成功
[root@hadoop001 software]$ java -version5、分发JDK
xsync /data/jdk1.8.0_212/6、分发环境变量
sudo ~/bin/xsync /etc/profile.d/my_env.sh7、分别在hadoop002、hadoop003、hadoop004、hadoop005、hadoop006上执行source
[root@hadoop002 data]$ source /etc/profile.d/my_env.sh
[root@hadoop003 data]$ source /etc/profile.d/my_env.sh
[root@hadoop004 data]$ source /etc/profile.d/my_env.sh
[root@hadoop005 data]$ source /etc/profile.d/my_env.sh
[root@hadoop006 data]$ source /etc/profile.d/my_env.shZookeeper安装
1、上传软件包到hadoop001:/opt/software并解压
# 解压文件到/data
[root@hadoop001 software]$ tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz -C /data/
# 重命名apache-zookeeper-3.6.3-bin名称为zookeeper-3.6.3
[root@hadoop001 data]$ mv apache-zookeeper-3.6.3-bin/ zookeeper-3.6.3
# 同步/data/zookeeper-3.6.3目录内容到hadoop002、hadoop003
[root@hadoop001 data]$ xsync zookeeper-3.6.3/2、配置服务器编号
# 在/data/datas目录下创建zookeeper用于存储zookeeper数据
[root@hadoop001 zookeeper-3.6.3]$ mkdir /data/datas/zookeeper
# 在/data/datas/zookeeper目录下创建一个myid的文件
[root@hadoop001 zkData]$ vim myid
# 添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
# 在文件中添加与server对应的编号:
1
# 拷贝配置好的zookeeper到其他机器上
[root@hadoop001 zookeeper]$ xsync myid
#并分别在hadoop002、hadoop003上修改myid文件中内容为2、33、配置zoo.cfg文件
# 重命名/data/zookeeper-3.6.3/conf这个目录下的zoo_sample.cfg为zoo.cfg
[root@hadoop001 conf]$ mv zoo_sample.cfg zoo.cfg
# 打开zoo.cfg文件
[root@hadoop001 conf]$ vim zoo.cfg
# 修改数据存储路径配置
dataDir=/data/datas/zookeeper
# 增加如下配置
#######################cluster##########################
server.1=hadoop001:2888:3888
server.2=hadoop002:2888:3888
server.3=hadoop003:2888:3888
# 同步zoo.cfg配置文件
[root@hadoop001 conf]$ xsync zoo.cfg4、配置日志输出路径
# 修改zookeeper/bin目录下zkEnv.sh
# 配置ZOO_LOG_DIR
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/data/logs/zookeeper"
fi# 修改zookeeper/bin目录下zkServer.sh
# 配置_ZOO_DAEMON_OUT
_ZOO_DAEMON_OUT="$ZOO_LOG_DIR/zookeeper.log"ZK集群启停脚本
新建文件 /root/bin/zk.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop001 hadoop002 hadoop003
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/data/zookeeper-3.6.3/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop001 hadoop002 hadoop003
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/data/zookeeper-3.6.3/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop001 hadoop002 hadoop003
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/data/zookeeper-3.6.3/bin/zkServer.sh status"
done
};;
esac增加脚本执行权限
chmod +x zk.shHadoop安装
1、上传hadoop软件包到hadoop001:/opt/software 并解压
tar -zxvf hadoop-3.1.3.tar.gz -C /data/2、添加hadoop环境变量
sudo vim /etc/profile.d/my_env.sh#HADOOP_HOME
export HADOOP_HOME=/data/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#root用户运行hadoop
export HADOOP_SHELL_EXECNAME=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root3、分发环境变量文件
[root@hadoop001 hadoop-3.1.3]$ sudo ~/bin/xsync /etc/profile.d/my_env.sh4、source一下,使之生效(6台节点)
[root@hadoop001 data]$ source /etc/profile.d/my_env.sh
[root@hadoop002 data]$ source /etc/profile.d/my_env.sh
[root@hadoop003 data]$ source /etc/profile.d/my_env.sh
[root@hadoop004 data]$ source /etc/profile.d/my_env.sh
[root@hadoop005 data]$ source /etc/profile.d/my_env.sh
[root@hadoop006 data]$ source /etc/profile.d/my_env.sh配置集群
1、core-site.xml
- 创建/data/datas/hadoop存储namenode和datanode数据
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode HA的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/datas/hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 配置该root(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<!--配置开启trash功能 文件保留三天 -->
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>
<!--定时检查Trash目录清理过期文件的周期 -->
<property>
<name>fs.trash.checkpoint.interval</name>
<value>60</value>
</property>
</configuration>2、hdfs-site.xml
- 创建/data/datas/hadoop/jn用于存储journalnode数据
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 测试环境指定HDFS副本的数量3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop001:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop002:8020</value>
</property>
<!--声明journalnode集群服务器-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/mycluster</value>
</property>
<!-- 与journal通信默认20秒容易超时这里设置90秒 -->
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>60000</value>
</property>
<!--声明journalnode服务器数据存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/datas/hadoop/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--datanode同时处理请求的任务上限默认4096改为最大值8192-->
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
</property>
</configuration>3、yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>:
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<!-- yarn容器允许管理的CPU核数大小 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>6</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>6</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop001:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--启用ResourceManager的高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指代ResourceManager HA的两台RM的逻辑名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmhacluster1</value>
</property>
<!--指定该高可用ResourceManager下的两台ResourceManager的逻辑名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--指定第一台ResourceManager服务器所在的主机名称 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop001</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop002</value>
</property>
<!--指定resourcemanager的web服务器的主机名和端口号-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop001:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop002:8088</value>
</property>
<!--做ResourceManager HA故障切换用到的zookeeper集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<!-- 指定NM端口地址 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:8043</value>
</property>
</configuration>4、mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop001:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop001:19888</value>
</property>
<!-- 指定AM端口范围 -->
<property>
<name>yarn.app.mapreduce.am.job.client.port-range</name>
<value>30000-30020</value>
</property>
</configuration>5、capacity-scheduler.xml
- 0.1 -> 1 增加AM内存大小 默认总大小的0.1
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>6、workers
hadoop001
hadoop002
hadoop003
hadoop004
hadoop005
hadoop006分发配置文件到hadoop002、hadoop003、hadoop004、hadoop005、hadoop006
xsync /data/hadoop-3.1.3/etc/hadoop7、日志、PID文件存储:hadoop-env.sh
- 创建路径/data/logs/hadoop、/data/pids/hadoop
export HADOOP_LOG_DIR=/data/logs/hadoop
export HADOOP_PID_DIR=/data/pids/hadoop格式化相关操作
1、在指定的所有journalnode机器上执行命令启动journalnode!!!
hdfs --daemon start journalnode2、在hadoop001机器上执行namenode格式化(zk进程所在节点)
hdfs namenode -format3、在hadoop001启动namenode
hdfs --daemon start namenode4、在hadoop002同步active namenode信息,作为备用namenode
hdfs namenode -bootstrapStandby5、在active namenode所在节点hadoop001执行,初始化zookeeper上NameNode的状态
hdfs zkfc -formatZK6、hadoop001节点上执行start-dfs.sh 启动ha,然后执行start-yarn.sh启动resourcemanager、nodemanager
hadoop集群启停脚本
新建文件/root/bin/hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop001 "/data/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop001 "/data/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop001 "/data/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop001 "/data/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop001 "/data/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop001 "/data/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac赋予执行权限
chmod +x hdp.shSpark安装
1、上传spark软件包到/opt/software并解压
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /data
cd /data# 重命名
mv spark-3.0.0-bin-hadoop3.2 spark2、添加环境变量
# SPARK_HOME
export SPARK_HOME=/data/spark
export PATH=$PATH:$SPARK_HOME/bin3、编辑conf/spark-env.sh
export JAVA_HOME=/data/jdk1.8.0_212
YARN_CONF_DIR=/data/hadoop-3.1.3/etc/hadoop
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://mycluster/spark-history
-Dspark.history.retainedApplications=30"
# 重定义spark pid文件存储路径
export SPARK_PID_DIR=/data/pids/spark
# 重定义log日志存储路径
export SPARK_LOG_DIR=/data/logs/spark
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop001,hadoop002,hadoop003
-Dspark.history.retainedApplications=30"
# 定期清理spark根目录下work文件夹
export SPARK_WORKER_OPTS="
-Dspark.worker.cleanup.enabled=true
-Dspark.worker.cleanup.interval=1800
-Dspark.worker.cleanup.appDataTtl=3600"
# worker可用核数
SPARK_WORKER_CORES=12
# worker可用内存
SPARK_WORKER_MEMORY=22g
# worker端口号
SPARK_WORKER_PORT=8988
# worker前端端口号 默认8081会和azkaban冲突
SPARK_WORKER_WEBUI_PORT=89874、新建文件conf/spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/spark-history
spark.yarn.historySevrer.address=hadoop001:18080
spark.history.ui.port=18080
spark.history.fs.cleaner.maxAge 7d
# 指定driver 和 executor端口范围
spark.driver.port=10000
spark.blockManager.port=20000
# 重试20次代表driver端口范围10000-10020,executor端口范围20000-20020
spark.port.maxRetries=20
# 指定压缩格式 国产服务器可能会使用
spark.shuffle.mapStatus.compression.codec lz45、hadoop集群创建文件夹spark-history
hadoop fs -mkdir /spark-history6、测试
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
107、spark读取hive元数据配置
- 配置文件路径:/data/spark-3.0.0/conf 添加文件hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://mysql_host:3306/metastore?useSSL=false&createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mysql_password</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>spark集群启停脚本
新建文件/root/bin/spark.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 spark集群 ==================="
echo " --------------- 启动 master ---------------"
ssh hadoop001 "/data/spark-3.0.0/sbin/start-master.sh"
echo " --------------- 30秒后启动 worker ---------------"
sleep 30
ssh hadoop001 "/data/spark-3.0.0/sbin/start-slaves.sh"
;;
"stop")
echo " =================== 关闭 spark集群 ==================="
ssh hadoop001 "/data/spark-3.0.0/sbin/stop-all.sh"
;;
*)
echo "Input Args Error..."
;;
esacSPARK-HA配置(可选)
1、角色分配
- hadoop001 master/worker
- hadoop002 master2/worker
- hadoop003 hadoop004 hadoop005 hadoop006 worker
2、spark-env.sh
# Master监控页默认访问端口为8080但是可能会和zookeeper冲突,所以改成8989,也可以自定义
# 重定义spark pid文件存储路径
export SPARK_PID_DIR=/data/pids/spark
# 重定义log日志存储路径
export SPARK_LOG_DIR=/data/logs/spark
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001,hadoop002,hadoop003 -Dspark.deploy.zookeeper.dir=/spark -Dspark.history.retainedApplications=30"
# 指定当前机器最多分配核数和内存大小
SPARK_WORKER_CORES=6
SPARK_WORKER_MEMORY=10g
# 修改 worker 端口号
SPARK_WORKER_PORT=8988
SPARK_WORKER_WEBUI_PORT=89873、spark-defaults.conf
- 配置yarn关联spark历史服务器
- /spark-history 该路径需要hdfs先创建
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/spark-history
spark.yarn.historySevrer.address=hadoop001:18080
spark.history.ui.port=18080
# 增加资源排队等待时间
spark.sql.broadcastTimeout=3600
spark.history.fs.cleaner.maxAge 7d
# 生产spark文件副本数 默认使用hadoop hdfs中配置
# spark.hadoop.dfs.replication=34、slaves
# 添加worker
hadoop001
hadoop002
hadoop003
hadoop004
hadoop0055、启动集群
# haoop001 spark根目录下执行
sbin/start-all.sh6、启动备用master
# 切换到hadoop002 spark根目录下执行
sbin/start-master.sh7、启动spark历史服务器
# haoop001 spark根目录下执行
sbin/start-history-server.shmysql安装
- 检查当前系统是否安装过mysql
rpm -qa | grep mariadb卸载安装
sudo rpm -e --nodeps mariadb-libs需要先安装mysql安装MySQL依赖
安装MySQL依赖
[root@hadoop001 software]$ sudo rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
[root@hadoop001 software]$ sudo rpm -ivh 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
[root@hadoop001 software]$ sudo rpm -ivh 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm安装mysql-client
[root@hadoop001 software]$ sudo rpm -ivh 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm安装mysql-server
[root@hadoop001 software]$ sudo rpm -ivh 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm启动MySQL
sudo systemctl start mysqld查看MySQL密码
sudo cat /var/log/mysqld.log | grep password配置MySQL
用刚刚查到的密码进入MySQL
mysql -uroot -p'password'更改MySQL密码策略
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;设置简单好记的密码
mysql> set password=password("000000");进入MySQL库
mysql> use mysql查询user表
mysql> select user, host from user;修改user表,把Host表内容修改为%
mysql> update user set host="%" where user="root";刷新
mysql> flush privileges;退出
mysql> quit;导出hive数据到关系库时,sqoop可能报错
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Data source rejected establishment of connection, message from server: "Too many connections"mysql设定的并发连接数太少或者系统繁忙导致连接数被占满。
解决办法:
编辑/etc/my.cnf,添加
# 在[mysqld] 下面添加下面三行
max_connections=1000
max_user_connections=500
wait_timeout=28800max_connections设置最大连接数为1000
max_user_connections设置每用户最大连接数为500
wait_timeout表示200秒后将关闭空闲(IDLE)的连接,但是对正在工作的连接不影响。默认28800
将mysql驱动放置到 hive/lib下
mysql-connector-java-5.1.27-bin.jarSpark Thrift Server
- $SPARK_HOME/conf下创建hive-site.xml文件配置连接mysql信息
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop001:3306/metastore?useSSL=false&createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>启动脚本
#!/bin/bash
SPARK_LOG_DIR=/data/logs/spark
if [ ! -d $SPARK_LOG_DIR ]
then
mkdir -p $SPARK_LOG_DIR
fi
# 检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process() {
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -ntlp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function spark_thrift_server_start() {
server2pid=$(check_process HiveThriftServer2 10000)
cmd="nohup start-thriftserver.sh --hiveconf hive.server2.thrift.port=10000 --master spark://hadoop001:7077 --executor-memory 1g --total-executor-cores 6 --num-executors 6 >$SPARK_LOG_DIR/spark_thrift_server.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "SparkThriftServer服务已启动"
}
function spark_thrift_server_stop() {
server2pid=$(check_process HiveThriftServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "SparkThriftServer服务未启动"
}
case $1 in
"start")
spark_thrift_server_start
;;
"stop")
spark_thrift_server_stop
;;
"restart")
spark_thrift_server_stop
sleep 2
spark_thrift_server_start
;;
"status")
check_process HiveThriftServer2 10000 >/dev/null && echo "SparkThriftServer服务运行正常" || echo "SparkThriftServer服务运行异常"
;;
"*")
echo "Invalid Args!"
echo "Usage: '$(basename $0)' start|stop|restart|status"
;;
esacHIVE On Spark
1、上传hive软件包到/opt/software并解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /data2、上传纯净版spark jar包到hadoop集群
- hive on spark 上传hdfs的jar必须是without-hadoop的不然会jar包冲突
# 上传并解压spark-3.0.0-bin-without-hadoop.tgz
tar -zxvf spark-3.0.0-bin-without-hadoop.tgz
# 上传spark纯净版jar包到hdfs
hadoop fs -mkdir /spark-jars
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars3、添加环境变量
# HIVE_HOME
export HIVE_HOME=/data/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin4、解决日志冲突,重命名日志包 hive/lib目录下执行
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak5、配置hive元数据到mysql
编辑conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop001:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--Spark依赖位置-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://mycluster/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>90000ms</value>
</property>
<property>
<name>spark.home</name>
<value>/data/spark</value>
</property>
<property>
<name>spark.master</name>
<value>yarn</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>1g</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>1g</value>
</property>
<property>
<name>spark.driver.cores</name>
<value>1</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>3</value>
</property>
<property>
<name>spark.executor.instances</name>
<value>2</value>
</property>
<property>
<name>hive.merge.sparkfiles</name>
<value>true</value>
</property>
<property>
<name>hive.insert.into.multilevel.dirs</name>
<value>true</value>
<description>允许生成多级目录</description>
</property>
<property>
<name>hive.exec.stagingdir</name>
<value>/tmp/hive/staging/.hive-staging</value>
<description>临时文件暂放目录解决datax导出路径文件会包含临时文件问题</description>
</property>
</configuration>6、创建spark配置文件
新建conf/spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
spark.executor.cores 3
spark.driver.cores 1
spark.executor.instances 2
# 小文件合并
hive.merge.sparkfiles true
spark.history.fs.cleaner.maxAge 7d
# 指定driver 和 executor端口范围
spark.driver.port=10000
spark.blockManager.port=20000
# 重试20次代表driver端口范围10000-10020,executor端口范围20000-20020
spark.port.maxRetries=20spark-history路径需要手动创建
7、拷贝mysql驱动包到lib目录
cp /opt/software/mysql-connector-java-5.1.27-bin.jar /data/hive-3.1.2/lib/8、初始化元数据库
mysql 创建数据库
create database metastore;登录mysql创建数据库metastore
执行初始化命令hive/bin目录下执行
schematool -initSchema -dbType mysql -verbose9、解决hive表注释中文乱码问题
- 进入数据库 Metastore 中执行以下 5 条 SQL 语句
(1)修改表字段注释和表注释
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;(2)修改分区字段注释
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;(3)修改索引注释
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;- 修改 metastore 的连接 URL
修改hive-site.xml配置文件
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://IP:3306/db_name?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>10、启动hive并测试
hive
create table student(id int, name string);
insert into table student values(1, 'abc');11、yarn容量调度器并发度问题解决办法(并发开启yarn任务出现阻塞)
增加ApplicationMaster资源比例
编辑hadoop/etc/hadoop/capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.5</value>
<description>
集群中用于运行应用程序ApplicationMaster的资源比例上限,
该参数通常用于限制处于活动状态的应用程序数目。该参数类型为浮点型,
默认是0.1,表示10%。所有队列的ApplicationMaster资源比例上限可通过参数
yarn.scheduler.capacity.maximum-am-resource-percent设置,而单个队列可通过参数yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent设置适合自己的值。
</description>
</property>分发capacity-scheler.xml配置文件并重启yarn即可
配置Yarn容量调度器多队列
修改容量调度器配置文件 capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hive</value>
<description>
再增加一个hive队列
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>50</value>
<description>
default队列的容量为50%
</description>
</property>
同时为新加队列添加必要属性
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>50</value>
<description>
hive队列的容量为50%
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
<description>
一个用户最多能够获取该队列资源容量的比例,取值0-1
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
<description>
hive队列的最大容量(自己队列资源不够,可以使用其他队列资源上限)
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
<description>
开启hive队列运行,不设置队列不能使用
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
<description>
访问控制,控制谁可以将任务提交到该队列,*表示任何人
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
<description>
访问控制,控制谁可以管理(包括提交和取消)该队列的任务,*表示任何人
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
<description>
指定哪个用户可以提交配置任务优先级
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name>
<value>-1</value>
<description>
hive队列中任务的最大生命时长,以秒为单位。任何小于或等于零的值将被视为禁用。
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name>
<value>-1</value>
<description>
hive队列中任务的默认生命时长,以秒为单位。任何小于或等于零的值将被视为禁用。
</description>
</property>分发capacity-scheler.xml配置文件并重启集群
任务指定任务队列节点名称
# 命令行
-Dmapreduce.job.queuename=hive
# hive客户端
set mapreduce.job.queuename=hive;sqoop任务指定任务队列名称
# 添加
-Dmapreduce.job.queuename=hive \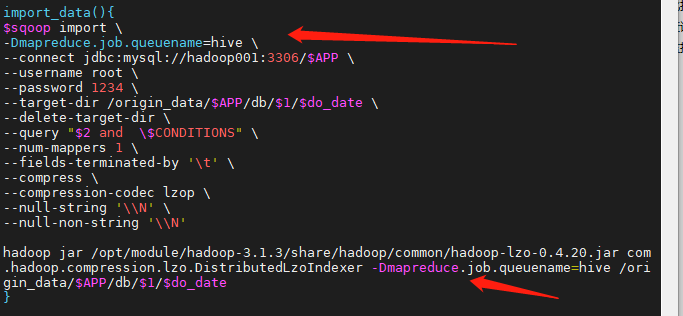
常见问题
1、在Sqoop中添加对HCatalog的支持后,要运行HCatalog作业需要添加以下环境变量
# HCAT_HOME
export HCAT_HOME=/data/hive-3.1.2/hcatalog
export PATH=$PATH:$HCAT_HOME/binHiveServer2高可用
hadoop001 hadoop002 hadoop003节点配置hiveserver2服务
编辑conf/hive-site.xml
<!-- hiveserver2高可用 -->
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop001</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>分别启动两个hiveserver2服务
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
# 检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process() {
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -ntlp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start() {
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hiveserver2 >$HIVE_LOG_DIR/hiveserver2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop() {
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
"*")
echo "Invalid Args!"
echo "Usage: '$(basename $0)' start|stop|restart|status"
;;
esac在zk上就可以看到服务注册列表
beeline命令
beeline -u 'jdbc:hive2://hadoop001:2181,hadoop002:2181,hadoop003:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk' -n root -e "SHOW DATABASES;"beeline命令不能包含sql注释语句否则会阻塞
hiveserver2记得修改内存大小,否则会oom
修改hive-env.sh
if [ "$SERVICE" = "cli" ]; then
if [ -z "$DEBUG" ]; then
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms500m -Xmx2048m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:+UseParNewGC -XX:-UseGCOverheadLimit"
else
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms500m -Xmx2048m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:-UseGCOverheadLimit"
fi
fi
export HADOOP_CLIENT_OPTS=" -Xmx3000m"
export HADOOP_HEAPSIZE=1024扩展功能: Supervisor管理hiveserver2服务
# start-hiveserver2.sh
HIVE_LOG_DIR=$HIVE_HOME/logs
cmd="nohup /data/hive-3.1.2/bin/hiveserver2 --hiveconf hive.execution.engine=spark spark.master=yarn >$HIVE_LOG_DIR/hiveserver2.log 2>&1"
eval $cmdMetastore高可用
修改hive-site.xml
<!--配置metastore高可用-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop001:9083,thrift://hadoop002:9083,thrift://hadoop003:9083</value>
</property>修改hive.sh自定义脚本
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
# 检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process() {
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -ntlp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start() {
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastore服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hiveserver2 >$HIVE_LOG_DIR/hiveserver2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop() {
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
"*")
echo "Invalid Args!"
echo "Usage: '$(basename $0)' start|stop|restart|status"
;;
esacSqoop安装
1、上传sqoop软件包到/opt/software并解压
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /data/
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop-1.4.62、修改配置文件
重命名 conf/sqoop-env-template.sh -> conf/sqoop-env.sh
编辑sqoop-env.sh
export HADOOP_COMMON_HOME=/data/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/data/hadoop-3.1.3
export HIVE_HOME=/data/hive-3.1.2
export ZOOKEEPER_HOME=/data/zookeeper-3.6.3
export ZOOCFGDIR=/data/zookeeper-3.6.3/conf3、拷贝jdbc驱动到lib目录
cp /opt/software/mysql-connector-java-5.1.27-bin.jar /data/sqoop-1.4.6/lib4、验证sqoop安装
bin/sqoop help
bin/sqoop list-databases --connect jdbc:mysql://hadoop001:3306 --username root --password 0000005、添加环境变量
# SQOOP_HOME
export SQOOP_HOME=/data/sqoop-1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
# HCAT_HOME
export HCAT_HOME=/data/hive-3.1.2/hcatalog
export PATH=$PATH:$HCAT_HOME/bin单独设置PID文件存储路径
当不修改PID文件位置时,系统默认会把PID文件生成到/tmp目录下,但是/tmp目录在一段时间后会被删除,所以以后当我们停止HADOOP/HBASE/SPARK时,会发现无法停止相应的进程
会警告说:no datanode to stop、no namenode to stop 等,因为PID文件已经被删除,此时只能用kill命令先干掉,所以现在我们需要修改HADOOP/HBASE/SPARK的PID文件位置。
修改配置前需要先停止集群。
1、创建pid存放目录:
mkdir -p /data/pids/hadoop
mkdir -p /data/pids/hbase
mkdir -p /data/pids/spark2、修改对应组件pid文件存储位置
# hadoop-env.sh
export HADOOP_PID_DIR=/data/pids/hadoop
# hbase-env.sh
export HBASE_PID_DIR=/data/pids/hbase
# spark-env.sh
export SPARK_PID_DIR=/data/pids/spark3、分发修改后的配置文件
4、启动集群后验证是否pid文件保存在指定的目录。
备用:单独启动服务
hdfs --daemon start datanode
yarn --daemon start nodemanager 存储格式
- Hive表存储使用orc+snappy
- orc的blocksize默认256M
- datax存储使用text+bzip2
- ods使用orc格式在dwd层读取计算结果落盘文件会比较大

KAFKA
1、解压文件
tar -zxvf kafka_2.12-3.0.0.tgz -C /data/
mv kafka_2.12-3.0.0/ kafka-3.0.02、配置文件
server.properties
broker.id=0 # 设置每台broker服务器的id 唯一值
delete.topic.enable=true
log.dirs=/data/datas/kafka # 设置kafka数据存储路径
log.retention.hours=168 # 数据保留时长
log.segment.bytes=1073741824 # 每个文件的大小
# zookeeper集群
zookeeper.connect=hadoop001:2181,hadoop002:2181,hadoop003:21813、配置环境变量
export KAFKA_HOME=/data/kafka-3.0.0
export PATH=$PATH:$KAFKA_HOME/bin
# 环境生效
source /etc/profile4、分发文件
# 分发文件
xsync kafka-3.0.0/5、修改日志存储目录
编辑kafka根目录下bin/kafka-run-class.sh
# 指定kafka日志目录
LOG_DIR=/data/logs/kafka
if [ ! -d $LOG_DIR ]; then
mkdir $LOG_DIR
fi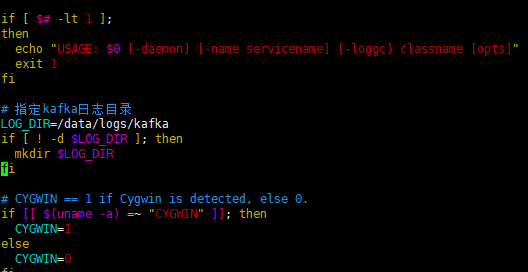
启停脚本 kafka.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop001 hadoop002 hadoop003
do
echo " --------启动 $i Kafka-------"
ssh $i "/data/kafka-3.0.0/bin/kafka-server-start.sh -daemon /data/kafka-3.0.0/config/server.properties"
done
};;
"stop"){
for i in hadoop001 hadoop002 hadoop003
do
echo " --------停止 $i Kafka-------"
ssh $i "/data/kafka-3.0.0/bin/kafka-server-stop.sh stop"
done
};;
esac端口号一览表
| 2888 | zookeeper通信 |
| 3888 | zookeeper通信 |
| 8020 | hdfs |
| 9870 | hdfs-webui |
| 9866 | datanode |
| 9864 | datanode-webui |
| 8088 | yarn-rm-webui |
| 30000-30020 | yarn-am-port |
| 8040-8049 | yarn-nm-port |
| 8030-8033 | yarn-service |
| 19888 | yarn-history |
| 10020 | mapred-history |
| 8485 | journalnode |
| 4040-4050 | spark-job-webui |
| 8989 | spark-master-webui |
| 8988 | spark-worker |
| 8987 | spark-worker-webui |
| 7077 | spark-master |
| 18080 | spark-history |
| 10000-10020 | spark-driver-port |
| 20000-20020 | spark-executor-port |
| 8081 | azkaban-webui |
| 12321 | azkaban-executor |
| 9083 | hive metastore |
添加至防火墙
firewall-cmd --permanent --add-port=2888/tcp
firewall-cmd --permanent --add-port=3888/tcp
firewall-cmd --permanent --add-port=8020/tcp
firewall-cmd --permanent --add-port=9083/tcp
firewall-cmd --permanent --add-port=9870/tcp
firewall-cmd --permanent --add-port=9866/tcp
firewall-cmd --permanent --add-port=9864/tcp
firewall-cmd --permanent --add-port=8088/tcp
firewall-cmd --permanent --add-port=8480/tcp
firewall-cmd --permanent --add-port=8989/tcp
firewall-cmd --permanent --add-port=7077/tcp
firewall-cmd --permanent --add-port=8987/tcp
firewall-cmd --permanent --add-port=8988/tcp
firewall-cmd --permanent --add-port=4040/tcp
firewall-cmd --permanent --add-port=4041/tcp
firewall-cmd --permanent --add-port=4042/tcp
firewall-cmd --permanent --add-port=4043/tcp
firewall-cmd --permanent --add-port=4044/tcp
firewall-cmd --permanent --add-port=4045/tcp
firewall-cmd --permanent --add-port=4046/tcp
firewall-cmd --permanent --add-port=4047/tcp
firewall-cmd --permanent --add-port=4048/tcp
firewall-cmd --permanent --add-port=4049/tcp
firewall-cmd --permanent --add-port=4050/tcp
firewall-cmd --permanent --add-port=8019/tcp
firewall-cmd --permanent --add-port=8030/tcp
firewall-cmd --permanent --add-port=8031/tcp
firewall-cmd --permanent --add-port=8032/tcp
firewall-cmd --permanent --add-port=8033/tcp
firewall-cmd --permanent --add-port=8040/tcp
firewall-cmd --permanent --add-port=8041/tcp
firewall-cmd --permanent --add-port=8042/tcp
firewall-cmd --permanent --add-port=8043/tcp
firewall-cmd --permanent --add-port=8044/tcp
firewall-cmd --permanent --add-port=8045/tcp
firewall-cmd --permanent --add-port=8046/tcp
firewall-cmd --permanent --add-port=8047/tcp
firewall-cmd --permanent --add-port=8048/tcp
firewall-cmd --permanent --add-port=8049/tcp
firewall-cmd --permanent --add-port=8081/tcp
firewall-cmd --permanent --add-port=12321/tcp
firewall-cmd --permanent --add-port=8485/tcp
firewall-cmd --permanent --add-port=10000/tcp
firewall-cmd --permanent --add-port=10001/tcp
firewall-cmd --permanent --add-port=10002/tcp
firewall-cmd --permanent --add-port=10003/tcp
firewall-cmd --permanent --add-port=10004/tcp
firewall-cmd --permanent --add-port=10005/tcp
firewall-cmd --permanent --add-port=10006/tcp
firewall-cmd --permanent --add-port=10007/tcp
firewall-cmd --permanent --add-port=10008/tcp
firewall-cmd --permanent --add-port=10009/tcp
firewall-cmd --permanent --add-port=10010/tcp
firewall-cmd --permanent --add-port=10011/tcp
firewall-cmd --permanent --add-port=10012/tcp
firewall-cmd --permanent --add-port=10013/tcp
firewall-cmd --permanent --add-port=10014/tcp
firewall-cmd --permanent --add-port=10015/tcp
firewall-cmd --permanent --add-port=10016/tcp
firewall-cmd --permanent --add-port=10017/tcp
firewall-cmd --permanent --add-port=10018/tcp
firewall-cmd --permanent --add-port=10019/tcp
firewall-cmd --permanent --add-port=10020/tcp
firewall-cmd --permanent --add-port=20000/tcp
firewall-cmd --permanent --add-port=20001/tcp
firewall-cmd --permanent --add-port=20002/tcp
firewall-cmd --permanent --add-port=20003/tcp
firewall-cmd --permanent --add-port=20004/tcp
firewall-cmd --permanent --add-port=20005/tcp
firewall-cmd --permanent --add-port=20006/tcp
firewall-cmd --permanent --add-port=20007/tcp
firewall-cmd --permanent --add-port=20008/tcp
firewall-cmd --permanent --add-port=20009/tcp
firewall-cmd --permanent --add-port=20010/tcp
firewall-cmd --permanent --add-port=20011/tcp
firewall-cmd --permanent --add-port=20012/tcp
firewall-cmd --permanent --add-port=20013/tcp
firewall-cmd --permanent --add-port=20014/tcp
firewall-cmd --permanent --add-port=20015/tcp
firewall-cmd --permanent --add-port=20016/tcp
firewall-cmd --permanent --add-port=20017/tcp
firewall-cmd --permanent --add-port=20018/tcp
firewall-cmd --permanent --add-port=20019/tcp
firewall-cmd --permanent --add-port=20020/tcp
firewall-cmd --permanent --add-port=30000/tcp
firewall-cmd --permanent --add-port=30001/tcp
firewall-cmd --permanent --add-port=30002/tcp
firewall-cmd --permanent --add-port=30003/tcp
firewall-cmd --permanent --add-port=30004/tcp
firewall-cmd --permanent --add-port=30005/tcp
firewall-cmd --permanent --add-port=30006/tcp
firewall-cmd --permanent --add-port=30007/tcp
firewall-cmd --permanent --add-port=30008/tcp
firewall-cmd --permanent --add-port=30009/tcp
firewall-cmd --permanent --add-port=30010/tcp
firewall-cmd --permanent --add-port=30011/tcp
firewall-cmd --permanent --add-port=30012/tcp
firewall-cmd --permanent --add-port=30013/tcp
firewall-cmd --permanent --add-port=30014/tcp
firewall-cmd --permanent --add-port=30015/tcp
firewall-cmd --permanent --add-port=30016/tcp
firewall-cmd --permanent --add-port=30017/tcp
firewall-cmd --permanent --add-port=30018/tcp
firewall-cmd --permanent --add-port=30019/tcp
firewall-cmd --permanent --add-port=30020/tcp
firewall-cmd --reload