Blog
flink-07 并行度
并行子任务和并行度
当要处理的数据量非常大时,我们可以把一个算子操作,复制多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行子任务(subtasks),再将他们分发到不同节点,就真正实现了并行计算。
在Flink执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask)这些子任务在不同的线程、不同的物理机或不同的容器中独立的执行。
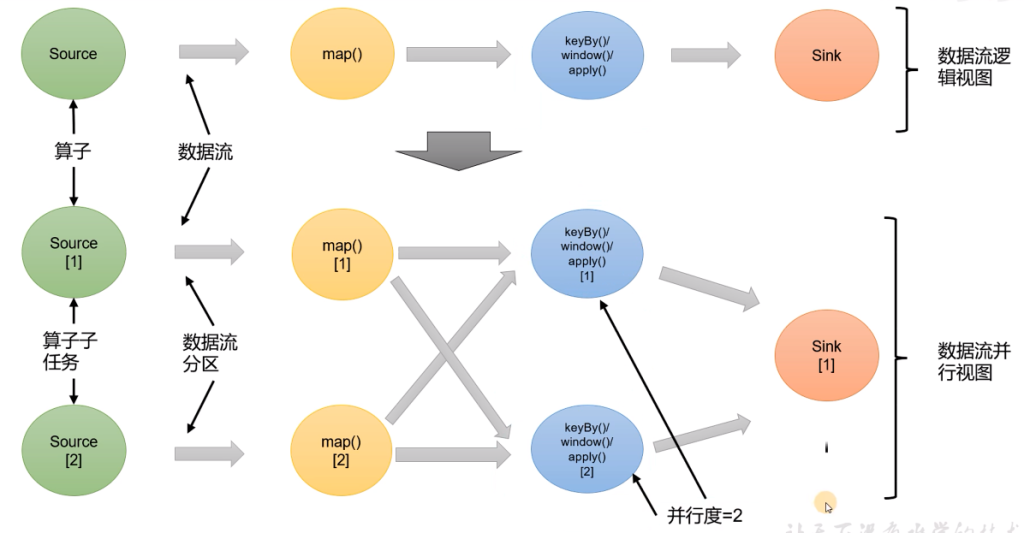
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中不同 的算子可能具有不同的并行度。
并行度的设置
- 在代码中设置
- 可以在算子后面跟着调用setParallelism()方法设置当前算子的并行度
- 只对当前算子有效
- 使用env.setParallelism()设置全局并行度
package com.learn.flink.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountUnboundedDemo {
public static void main(String[] args) throws Exception {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
DataStreamSource<String> socketDS = env.socketTextStream("hadoop003", 7777);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS
.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}).setParallelism(2)
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(value -> value.f0)
.sum(1);
sum.print();
env.execute();
}
}这里还需要添加包:在本地开启flink-webui方便查看
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>同时这里添加了provided 所以在运行的时候需要编辑运行配置 添加provided依赖
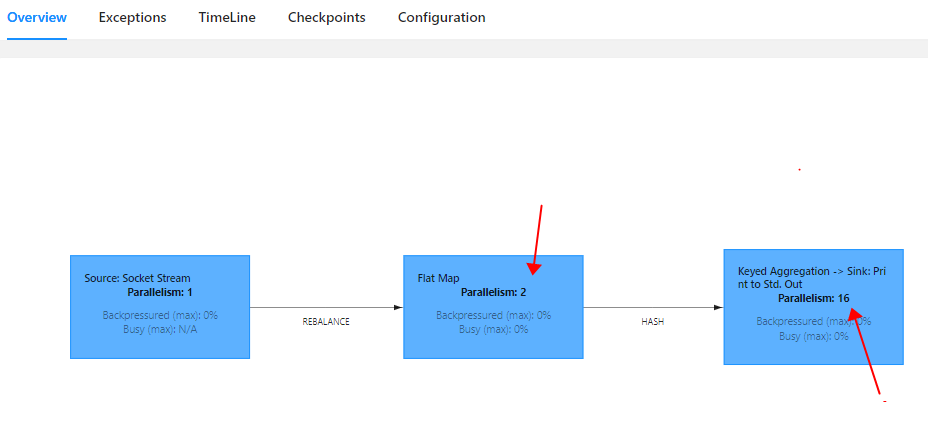
FlatMap的并行度为代码中设置的2,sink中的并行度16默认使用当前电脑的线程数(8核16线程)
并行度优先级:
算子 > env > 提交时指定 > 配置文件
算子链
一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通(forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式取决于算子的种类。
一对一(One to One, forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如图中的source和map算子,比如上面第一张图中的source和map算子,source算子读取数据之后,可以直接发送给map算子做处理,它们之间不需要重分区,也不需要调整数据的顺序。这就意味着map算子的子任务,看到元素的个数和顺序跟source算子的子任务产生的完全一样,保证着“一对一”的关系。map、filter、flatMap等算子都是这种一对一的对应关系。
重分区(redistributing)
在这种模式下,数据流的分区会发生变化。比如map和后面的keyby/window算子之间以及keyby/window和sink算子之间,都是这样的关系
每一个算子的子任务会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程。
合并算子链
在flink中,并行度相同的一对一的算子操作,可以直接链接在一起形成一个大的任务。这样原来的算子就成为了真正任务里的一部分。所以如下图,每个task会被一个现成执行。这样的技术被称为算子链(operator chain)
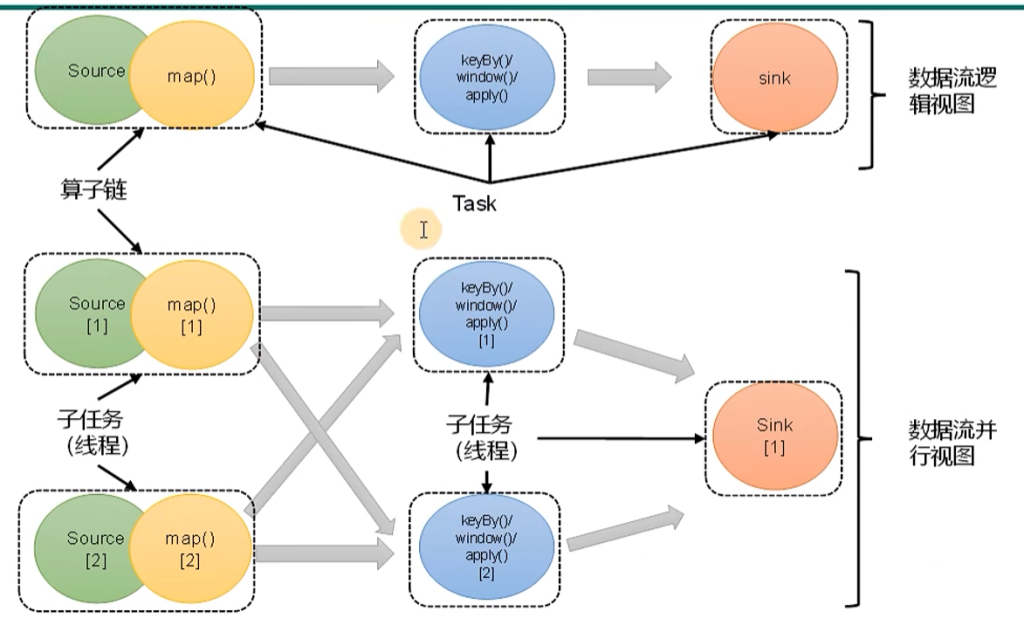
source子任务和map子任务合并成为一个子任务
将算子链接成task是非常有效的优化,可以减少现成之间的切换和基于缓存区的数据交换。在减少时延的同时提升吞吐量。
禁用算子链
// 禁用算子链
.map(xxx).disableChaining();
// 从当前算子开始新链
.map(xxx).startNewChain()全局禁用合并算子链
env.disableOperatorChaining();禁用算子链场景:flatMap计算逻辑复杂,Map计算逻辑也复杂 这时候需要分开