Blog
flink-27 状态管理
在flink中算子任务,可以分为无状态和有状态两种
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。之前讲到的基本转换算子map、filter、flatMap,计算时不依赖其他数据,都属于无状态的算子。

而有状态的算子任务,则除当前数据之外,还需要一些其他数据来得到计算结果。这里的其他数据就是所谓的状态。之前讲到的算子中:聚合算子、窗口算子都属于有状态的算子。
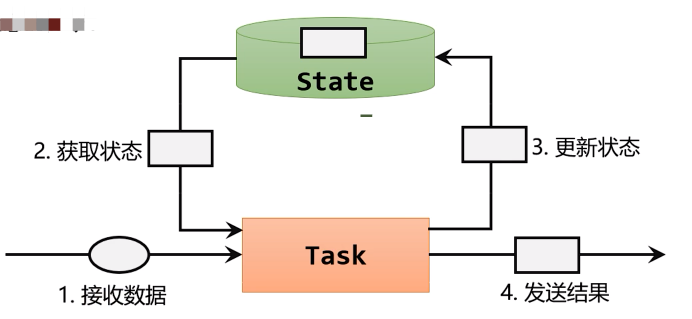
有状态算子的一般处理流程:
- 算子任务接收到上游发来的数据
- 获取当前状态
- 根据业务逻辑进行计算,更新状态
- 得到计算结果,输出发送到下游任务
状态的分类
- 托管状态(Managed State)和原始状态(Raw State)
- 托管状态就是由Flink统一管理的,状态从存储访问、故障恢复和重组等一些列问题都由flink实现,我们只要调用接口就可以
- 原始状态是自定义的,相当于开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复
- 通常我们采用flink托管状态来实现需求
托管状态
- 算子状态(Operator State)和按键分区状态(Keyed State)
- flink管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。
- 算子状态可以用在所有算子上,在使用时还需要进一步实现CheckpointedFuntion接口
- 新的source架构,则是需要基础SourceReaderBase抽象类
- KeyedState只针对当前key
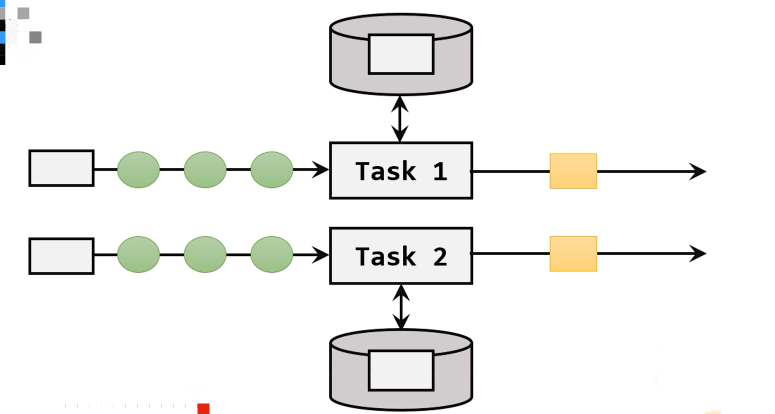
一个子任务中有多个key
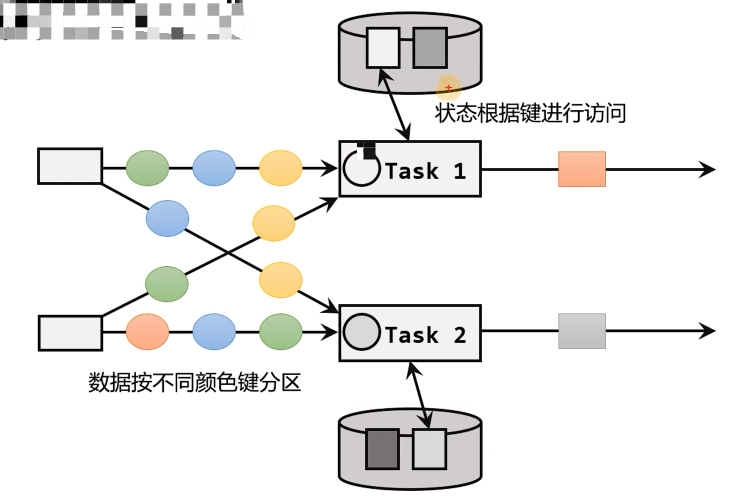
也可以通过富函数类来定义KeyedState,所以只要提供了富函数类接口的算子,也都可以使用KeyedState