Blog
flink-32 检查点配置
启用检查点
默认情况下flink是禁用检查点的,如果要开启需要在代码中显示的调用
// 每隔1秒启动一次检查点保存
env.enableCheckpointing(1000);不传参默认的间隔周期为500毫秒(已弃用)
package com.learn.flink.checkpoint;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class CheckConfigDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(1);
// 代码中用到hdfs,需要导入hadoop依赖 指定访问hdfs的用户名
System.setProperty("HADOOP_USER_NAME", "root");
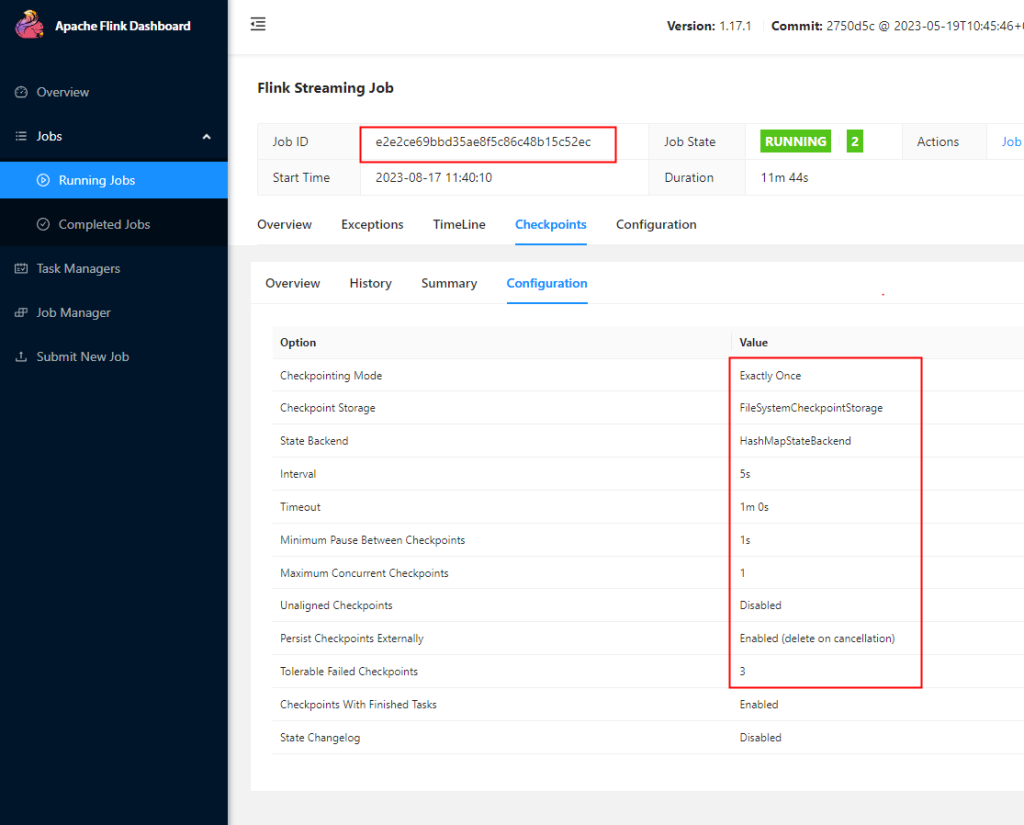
// TODO 检查点配置
// 1、启用检查点,默认是barrier对齐的,周期为5s,精准一次
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// 2、指定检查点的存储位置
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
// 使用hdfs需要导入hadoop-client依赖,不建议打包的时间将hadoop依赖打包scope设置provided即可
checkpointConfig.setCheckpointStorage("hdfs://hadoop001:8020/chk");
// 3、checkpoint的超时时间:默认10分钟
checkpointConfig.setCheckpointTimeout(60 * 1000L);
// 4、同时运行中的checkpoint的最大数量
checkpointConfig.setMaxConcurrentCheckpoints(1);
// 5、最小等待间隔:上一轮checkpoint结束 到下一轮 checkpoint开始之间的间隔,设置了大于0,并发就会变成1
checkpointConfig.setMinPauseBetweenCheckpoints(1000L);
// 6、取消作业时,checkpoint是否保留在外部系统
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);
// 7、允许checkpoint连续失败的次数,默认0,表示checkpoint一失败job就挂掉
checkpointConfig.setTolerableCheckpointFailureNumber(3);
DataStreamSource<String> socketDS = env.socketTextStream("hadoop003", 7777);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS
.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(value -> value.f0)
.sum(1);
sum.print();
env.execute();
}
}

默认保留最近的一次成功的checkpoint,可以设置保留个数,取消任务的时候chk-132就会被删除,因为设置了DELETE_ON_CANCELLATION,生产建议设置RETAIN_ON_CANCELLATION
DELETE_ON_CANCELLATION 如果程序突然挂掉而非取消,则无法删除chk-132
// 开启非对其检查点(barrier非对其)
// 开启要求: checkpoint模式必须时精准一次,最大并发必须设为1
checkpointConfig.enableUnalignedCheckpoints();// 开启非对齐检查点才生效:默认0,表示一开始就直接用 非对齐检查点
// 如果大于0,一开始用 对齐检查点(barrier对齐),对齐的时间超过这个参数,自动切换成 非对齐检查点(barrier非对齐)
checkpointConfig.enableUnalignedCheckpoints();
checkpointConfig.setAlignedCheckpointTimeout(Duration.ofSeconds(1));通用增量 checkpoint(changelog)
flink1.15开始不管hashmap还是rocksdb状态后端都可以通过开启changelog实现通用的增量checkpoint
- 执行过程
- 带状态的算子任务将状态写入变更日志(记录状态)
- 状态物化:状态表定期保存,独立于检查点
- 状态物化完成后,状态变更日志就可以被截断到相应的点
- 注意事项
- 目前标记为实验性功能,开启后可能会造成资源消耗增大
- hdfs上保存的文件数变多
- 消耗更多的IO带宽用于上传变更日志
- 更多的CPU用于序列化状态更改
- TaskManager使用更多内存来缓存状态更改
- 使用限制
- checkpoint的最大并发必须为1
- 从flink1.15开始,只有文件系统的存储类型实现可用(memory测试阶段)
- 不支持NO_CLAIM模式
- 目前标记为实验性功能,开启后可能会造成资源消耗增大
- 使用方式
(1)配置文件指定
state.backend.changelog.enabled: true
state.backend.changelog.storage: filesystem
# 存储changelog数据
dstl.dfs.base-path: hdfs://hadoop001:8020/changelog
execution.checkpointing.max-concurrent-checkpoints: 1
execution.savepoint-restore-mode: CLAIM(2)代码中设置
需要引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-changelog</artifactId>
<version>${flink.version}</version>
<scope>runtime</scope>
</dependency>开启changelog
// 开启changelog
// 要求checkpoint的最大并发必须为1 setMaxConcurrentCheckpoints 其他参数建议在flink-conf配置文件中去指定(参考方式一)
env.enableChangelogStateBackend(true);