Blog
flink-39 Flink sql 查询
准备
CREATE TABLE source (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.id.kind' = 'sequence',
'fields.id.start' = '1',
'fields.id.end' = '10000',
'fields.ts.kind' = 'sequence',
'fields.ts.start' = '1',
'fields.ts.end' = '1000000',
'fields.vc.kind' = 'random',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);
CREATE TABLE sink (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);WITH子句

WITH source_with_total AS (
SELECT id, vc+10 AS total
FROM source
)
SELECT id, SUM(total)
FROM source_with_total
GROUP BY id;自定义数据源
SELECT id,price FROM (VALUES(1,1.1),(2,2.2)) AS t (id, price);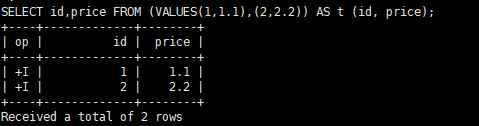
DISTINCT
对于流查询 计算查询结果所需的状态可能无限增长。状态大小取决于不同行数。
可以设置适当的状态生存时间TTL,以防止状态过大。但是这可能会影响查询效果的正确性。某个key的数据过期从状态中删除了,那么下次再来这么一个key,由于在状态中找不到就会又输出一遍
分组聚合
CREATE TABLE source1 (
dim STRING,
user_id BIGINT,
price BIGINT,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.dim.length' = '1',
'fields.user_id.min' = '1',
'fields.user_id.max' = '100000',
'fields.price.min' = '1',
'fields.price.max' = '100000'
);
CREATE TABLE sink1 (
dim STRING,
pv BIGINT,
sum_price BIGINT,
max_price BIGINT,
min_price BIGINT,
uv BIGINT,
window_start BIGINT
) WITH (
'connector' = 'print'
);
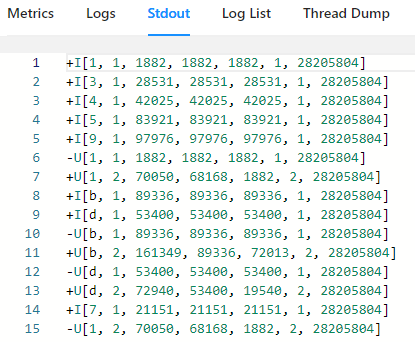
-- 统计每个维度dim 每分钟的指标
INSERT INTO sink1
SELECT dim,
count(1) as pv,
sum(price) as sum_price,
max(price) as max_price,
min(price) as min_price,
count(distinct user_id) as uv,
cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as BIGINT) as window_start
FROM source1
GROUP BY dim, cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as BIGINT);- cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as BIGINT) 秒级时间戳 / 60 转化为1min
- UNIX_TIMESTAMP 得到秒级的时间戳
多维分析
分组聚合页支持Grouping sets、Rollup、Cube
- Rollup 维度由细越来越粗
- (supplier_id, product_id, rating), (supplier_id, product_id), (supplier_id), ()
- Cube 维度由粗越来约细
SELECT supplier_id,
rating,
product_id,
count(1) cnt
FROM (
VALUES
('supplier1', 'product1', 4),
('supplier1', 'product1', 3),
('supplier2', 'product1', 3),
('supplier2', 'product1', 4)
) AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS ( (supplier_id, product_id, rating), (supplier_id, product_id), (supplier_id, rating), (supplier_id), (rating), ());分组窗口聚合
直接把窗口自身作为分组key放在GROUP BY之后 叫做分组窗口聚合
SQL中只支持基于时间的窗口,不支持基于元素个数的窗口
- TUMBLE(time_attr_column, interval)
- 滚动窗口
- 滚动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上
- HOP(time_attr_column, interval, interval)
- 滑动窗口
- 滑动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上
- SESSION(time_attr_column, interval)
- 会话窗口
- 会话窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上
辅助函数
- 窗口名_START
- 返回相对应的窗口的开始时间
- 窗口名_END
- 返回想对应窗口的结束时间
CREATE TABLE ws (
id INT,
vc INT,
pt AS PROCTIME(),
et AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR et as et - INTERVAL '5' SECOND
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.id.min' = '1',
'fields.id.max' = '3',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);滚动窗口示例(时间属性字段,窗口长度)
SELECT id,
TUMBLE_START(et, INTERVAL '5' SECOND) wstart,
TUMBLE_END(et, INTERVAL '5' SECOND) wend,
sum(vc) sumVc
FROM ws
GROUP BY id, TUMBLE(et, INTERVAL '5' SECOND);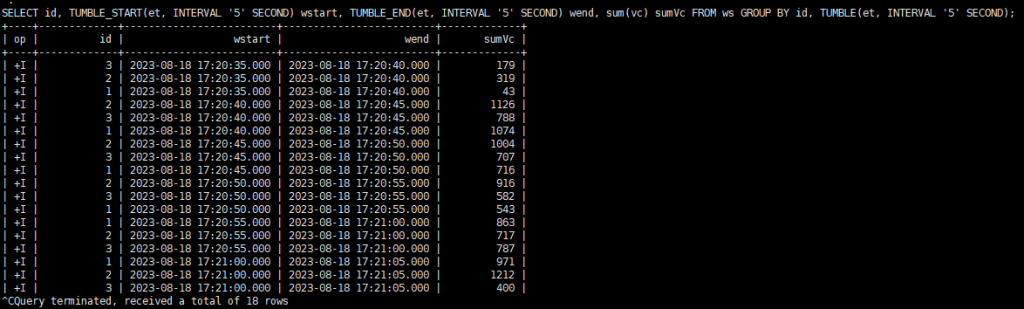
滑动窗口(时间属性字段,滑动步长, 窗口长度)
SELECT id,
HOP_START(et, INTERVAL '2' SECOND, INTERVAL '5' SECOND) wstart,
HOP_END(et, INTERVAL '2' SECOND, INTERVAL '5' SECOND) wend,
sum(vc) sumVc
FROM ws
GROUP BY id, HOP(et, INTERVAL '2' SECOND, INTERVAL '5' SECOND);会话窗口(时间属性字段,会话间隔时间)
SELECT id,
SESSION_START(et, INTERVAL '5' SECOND) wstart,
SESSION_END(et, INTERVAL '5' SECOND) wend,
sum(vc) sumVc
FROM ws
GROUP BY id, SESSION(et, INTERVAL '5' SECOND);窗口表值函数(TVF)聚合
对比窗口聚合优点
- 提供更多的性能优化手段
- 支持GroupingSets语法
- 可以在window聚合中使用TopN
- 提供累积窗口

滚动窗口
SELECT id,
sum(vc) as vcSum,
window_start,
window_end
FROM TABLE (
TUMBLE(TABLE ws, DESCRIPTOR(pt), INTERVAL '5' SECOND)
)
GROUP BY window_start, window_end, id;
- 滑动窗口
- 要求 窗口的大小是 滑动步长的 整数倍
- 底层会优化成多个小滚动窗口
SELECT id,
sum(vc) as vcSum,
window_start,
window_end
FROM TABLE (
HOP(TABLE ws, DESCRIPTOR(et), INTERVAL '2' SECOND, INTERVAL '6' SECOND)
)
GROUP BY window_start, window_end, id;- 累积窗口
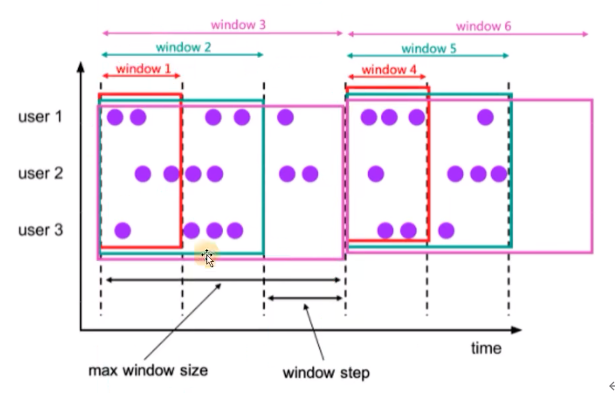
累积窗口会在一定的统计周期内进行累积计算。累积窗口中由两个核心的参数:最大窗口长度(max window size)和累积步长(step)
- 所谓的最大窗口长度其实就是我们所说的统计周期,最终目的就是统计这段时间内的数据。
- 其实就是固定窗口间隔内提前触发的滚动窗口
- Tumble Window + early-fire的一个事件时间的版本
- 比如从每日0点到当前时间,每隔一分钟打印一次累积UV
- 窗口最大长度 = 累积步长的整数倍
累积窗口可以认为是首先开一个最大窗口大小的滚动窗口,然后根据用户设置的触发事件间隔将这个滚动窗口拆分为多个窗口,这些窗口具有相同的窗口起点和不同的窗口终点。
SELECT id,
sum(vc) as vcSum,
window_start,
window_end
FROM TABLE (
CUMULATE(TABLE ws, DESCRIPTOR(et), INTERVAL '2' SECOND, INTERVAL '6' SECOND)
)
GROUP BY window_start, window_end, id;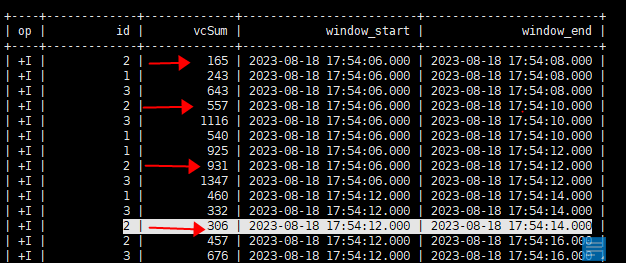
开始时间一样,随着时间推移 变大 下一个周期重新累积
- 多维分析
SELECT id,
sum(vc) as vcSum,
window_start,
window_end
FROM TABLE (
CUMULATE(TABLE ws, DESCRIPTOR(et), INTERVAL '2' SECOND, INTERVAL '6' SECOND)
)
GROUP BY window_start, window_end,
rollup((id));
-- cube((id))
-- grouping sets((id), ())OVER聚合

按照时间区间
统计每个传感器前10秒到现在收到的水位数据条数
SELECT id,
et,
vc,
count(vc) OVER (
PARTITION BY id
ORDER BY et
RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
) AS cnt
FROM ws;也可以WINDOW来在SELECT 外部单独定义一个OVER窗口,可以多次使用。
SELECT id,
et,
vc,
count(vc) OVER w AS cnt,
sum(vc) OVER w AS sumVC
FROM ws
WINDOW w AS (
PARTITION BY id
ORDER BY et
RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
);按照行数聚合
统计每个传感器前5条到现在数据的 平均 水位数
SELECT id,
et,
vc,
avg(vc) OVER w AS cnt
FROM ws
WINDOW w AS (
PARTITION BY id
ORDER BY et
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
);特殊语法 TopN

每个传感器最高的水位值
SELECT id, et, vc, rn
FROM (
SELECT id,
et,
vc,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY vc DESC) as rn
FROM ws
)
WHERE rn <= 3;Deduplication去重
排序字段一定是时间属性列,可以降序 不能是其他非时间属性的普通列

对每个传感器的水位值去重
SELECT id,et,vc, rn
FROM (
SELECT id, et, vc,
ROW_NUMBER() OVER (PARTITION BY id, vc ORDER BY et desc) AS rn
FROM ws
)
WHERE rn = 1;如果是按照时间属性字段降序,标识取最新一条,会造成不断的更新保存最后一条。如果是升序,标识取最早的一条,不用取更新,性能更好。
排序是普通列 则按照topn计算
联结(Join)查询
常规联结 Regular Join
- inner join
- 任务流中,只有两条流join到才输出 输出+[L, R]
- left join
- 任务流中,左流数据到达之后,无论有没有join到右流的数据,都会输出join结果 (join上输出+[L, R],没join上输出+[L, NULL])
- 如果右流到达之后,发现左流之前输出过没有join到的数据,则会发起撤回流,先输出-[L, R]然后输出+[L, R]
- right join
- 通left join 逻辑相反
- full join

Regular join注意事项
- 实时Regular join可以不是等值join。
- 等值join和非等值join区别在于,等值join数据shuffle策略是hash,会按照join on中的等值条件作为id发往对应的下游。
- 非等值join数据shuffle的策略是global,所有数据发往一个并发,按照非等值条件进行关联
- join的流程是左流新来一条数据之后,会和右流中符合条件的所有数据做join然后输出。
- 流的上游是无限的数据,所以要做到关联的话,flink会将两条流所有数据都存储在State中,所以flink任务的state会无限增大,因此需要为state配置合适的TTL,以防止state过大。
再准备一张表用于join
CREATE TABLE ws1 (
id INT,
vc INT,
pt AS PROCTIME(),
et AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR et as et - INTERVAL '0.001' SECOND
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.id.min' = '1',
'fields.id.max' = '3',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);间隔联结查询
目前flink sql还不支持窗口联结,而间隔联结已经实现
间隔联结Interval join返回的,同样是符合约束条件的两条数据中数据的笛卡尔积,只不过这里的约束条件除了常规联结条件之外,还多了一个时间间隔的限制
- 两张表的联结
- 间隔联结不需要用join关键字,直接再from后面讲要连接的两表列出来就可以,用逗号分隔
- 联结条件
- 联结条件用WHERE子句来定义,用一个等值表达式描述
- 时间间隔限制
- 我们可以在WHERE子句中,联结条件后用AND追加一个时间间隔的限制条件
- 提取左右两表中的事件字段用一个表达式指明两者需要满足的间隔限制
- ltime = rtime
- ltime >= ritime AND ltime < rtime + INTERVAL '10' MINUTE
- ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
SELECT *
FROM ws, ws1
WHERE ws.id = ws1.id
AND ws.et BETWEEN ws1.et - INTERVAL '2' SECOND AND ws1.et + INTERVAL '2' SECOND;
维度表join联结查询
Lookup Join其实就是为表Join,实时获取外部缓存的join。
Lookup的意思就是实时查找
上面说的几种join都是流与流之间的join,而lookup join是流与redis,mysql,hbase这种外部存储介质的join。仅支持处理时间字段
- 因为是 过来的数据 要查它到来的那一刻 维度表中对应的数据
表A
JOIN 维度表名 FOR SYSTEM_TIME AS OF 表A.proc_time AS 别名
ON 表A.字段 = 别名.字段Order by
支持Batch/Streaming但在实时任务中一般用的非常少
实时任务中Order By子句中必须要有时间属性字段,并且必须写在最前面且为升序
SQL Hints
在执行查询时,可以在表名后面加上SQL Hints来临时修改表属性,对当前job生效
- 主要修改的就是WITH中的参数
SELECT *
FROM ws1/*+ OPTIONS('rows-per-second'='10')*/;/*+ OPTIONS('X'='Y')*/集合操作
UNION 去重
UNION ALL 不去重
交集
INTERSECT 交集去重
INTERSECT ALL 交集不去重
差集
EXCEPT 差集去重
EXCEPT ALL 差集不去重
IN子查询
IN子查询的结果集只能有1列
in子查询也会涉及到大状态问题,要注意设置state的ttl