Blog
flink-45 UDF
UDF主要有以下几类:
- 标量函数 Scala Functions
- 一进一出
- 表函数 Table Functions
- 一进多出
- 聚合函数 Aggregate Functions
- 多进一出 聚合
- 表聚合函数 Table Aggregate Functions
- 多进 一出或多出
整体调用流程
- 注册函数
- 注册函数是需要调用表环境的createTemporarySystemFunction()方法
tableEnv.createTemporarySystemFunction("MyFunction", MyFunction.class)- 使用TableApi调用函数
- 使用call()方法来调用自定义函数
- call方法两个参数,一个是注册好的函数名,一个是函数调用时参数
tableEnv.from("MyTable").select(call("MyFunction", $("myField")));在sql中调用函数
tableEnv.sqlQuery("SELECT MyFunction(MyField) FROM MyTable");标量函数
package com.learn.flink.source;
import com.learn.flink.bean.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.api.Expressions;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.call;
public class MyScalaFunctionDemo {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> sensorDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 2L, 2),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3),
new WaterSensor("s3", 4L, 4)
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 流转表
Table sensorTable = tableEnv.fromDataStream(sensorDS);
tableEnv.createTemporaryView("sensor", sensorTable);
// 注册函数
tableEnv.createTemporaryFunction("hash_function", HashFunction.class);
// 调用自定义函数
// tableEnv.sqlQuery("SELECT hash_function(id) FROM sensor")
// .execute() // 调用了sql的execute就不需要env.execute()
// .print();
// table api 用法
sensorTable
.select(call("hash_function", Expressions.$("id")))
.execute()
.print();
}
// 自定义函数的实现类
public static class HashFunction extends ScalarFunction {
// 接收任意类型的输入,返回INT类型输出
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
}表函数
在SQL中调用表函数,需要使用LATERAL TABLE() 来生成扩展的侧向表,然后与原始表进行联结join
- 这里的join操作可以是直接做交叉联结cross join,在FROM后用逗号分隔两个表就可以
- 也可以ON TRUE为条件的左联结 LEFT JOIN
package com.learn.flink.source;
import com.learn.flink.bean.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.api.Expressions;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.call;
public class MyTableFunctionDemo {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> strDS = env.fromElements(
"hello flink",
"hello world hi",
"hello java"
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 流转表
Table strTable = tableEnv.fromDataStream(strDS, Expressions.$("words"));
tableEnv.createTemporaryView("str", strTable);
// 注册函数
tableEnv.createTemporaryFunction("split_function", SplitFunction.class);
// 调用自定义函数
tableEnv.sqlQuery("SELECT words, word, length FROM str, LATERAL TABLE(split_function(words))")
.execute()
.print();
}
// 集成TableFunction<返回的类型>
// 类型标准 ROW包含两个字段word和length
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public static class SplitFunction extends TableFunction<Row> {
// 返回必须是void 用collect方法输出
public void eval(String str) {
for (String word : str.split(" ")) {
collect(Row.of(word, word.length()));
}
}
}
}写法二
SELECT words, word, length FROM str LEFT JOIN LATERAL TABLE(split_function(words)) ON true;字段重命名
- AS 表名(字段名1,字段名2...)
SELECT words, newWord, newLength FROM str LEFT JOIN LATERAL TABLE(split_function(words)) AS T(newWord, newLength) ON true;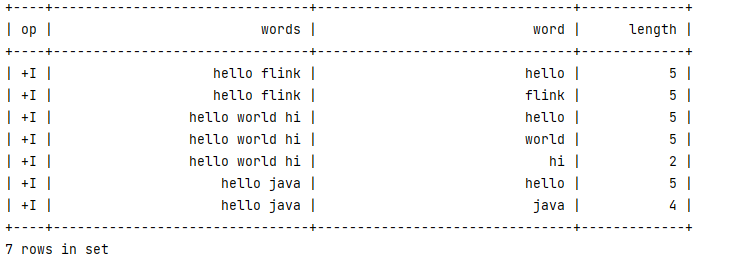
聚合函数
原理
- 首先需要创建一个累加器accmulator用来存储聚合的中间结果
- 累加器可以看作是一个聚合状态
- 调用createAccumulator()方法可以创建一个空的累加器
- 对于输入的每一行数据都会调用accumulate()方法来更新累加器
- 当所有数据都处理完成之后,通过调用getValue()方法来计算并返回最终的结果
package com.learn.flink.source;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.Expressions;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.AggregateFunction;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
public class MyAggregateFunctionDemo {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 分数 权重
DataStreamSource<Tuple3<String, Integer, Integer>> scoreWeightDS = env.fromElements(
Tuple3.of("s1", 80, 3),
Tuple3.of("s1", 90, 4),
Tuple3.of("s1", 95, 4),
Tuple3.of("s2", 75, 3),
Tuple3.of("s2", 65, 4),
Tuple3.of("s2", 85, 4)
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 流转表
Table scoreTable = tableEnv.fromDataStream(scoreWeightDS, Expressions.$("f0").as("name"), Expressions.$("f1").as("score"), Expressions.$("f2").as("weight"));
tableEnv.createTemporaryView("scores", scoreTable);
// 注册函数
tableEnv.createTemporaryFunction("weight_avg", WeightAvg.class);
// 调用自定义函数
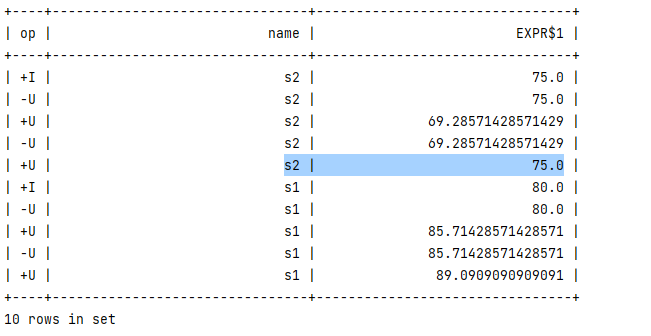
tableEnv.sqlQuery("SELECT name, weight_avg(score, weight) FROM scores GROUP BY name")
.execute()
.print();
}
// 泛型 第一个 返回的参数 第二个累加器类型<加权总和,权重总和>
public static class WeightAvg extends AggregateFunction<Double, Tuple2<Integer, Integer>> {
@Override
public Double getValue(Tuple2<Integer, Integer> item) {
return item.f0 * 1D / item.f1;
}
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0, 0);
}
/**
* 累加计算的方法 每来一条数据 就会执行一次
* @param acc 累加器类型
* @param score 分数
* @param weight 权重
*/
public void accumulate(Tuple2<Integer, Integer> acc, Integer score, Integer weight) {
acc.f0 += score * weight; // 加权综合= 分数1 * 权重1 + 分数2 * 权重2 + ...
acc.f1 += weight; // 权重和 = 权重1 + 权重2 + ...
}
}
}
表聚合函数
计算输入数据的top2
package com.learn.flink.source;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableAggregateFunction;
import org.apache.flink.util.Collector;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;
public class MyTableAggregateFunctionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> numDS = env.fromElements(3, 6, 9, 12, 5, 8, 9, 4);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 流转表
Table numTable = tableEnv.fromDataStream(numDS, $("num"));
// 注册函数
tableEnv.createTemporaryFunction("top2", Top2.class);
// 调用自定义函数 只支持TableApi
numTable
.flatAggregate(
call("top2", $("num")).as("value", "rank")
)
.select($("value"), $("rank"))
.execute()
.print();
}
// 返回类型(数值,排名)=》(12, 1) (9, 2)
// 累加器类型(第一大的数, 第二大的数)(12, 9)
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>> {
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0, 0);
}
/**
* 每来一个数据调用一次,比较大小,更新最大的前两个数到acc中
*
* @param acc 累加器
* @param num 过来的数据
*/
public void accumulate(Tuple2<Integer, Integer> acc, Integer num) {
if (num > acc.f0) {
// 新来的变第一,原来的变第二
acc.f1 = acc.f0;
acc.f0 = num;
} else if (num > acc.f1) {
// 新来的变第二, 原来的不要了
acc.f1 = num;
}
}
/**
* 输出结果(数值,排名) 两条最大的
*
* @param acc 累加器
* @param out 采集器
*/
public void emitValue(Tuple2<Integer, Integer> acc, Collector<Tuple2<Integer, Integer>> out) {
if (acc.f0 != 0) {
out.collect(Tuple2.of(acc.f0, 1));
}
if (acc.f1 != 0) {
out.collect(Tuple2.of(acc.f1, 2));
}
}
}
}