Blog
flume-04 进阶
Flume事务
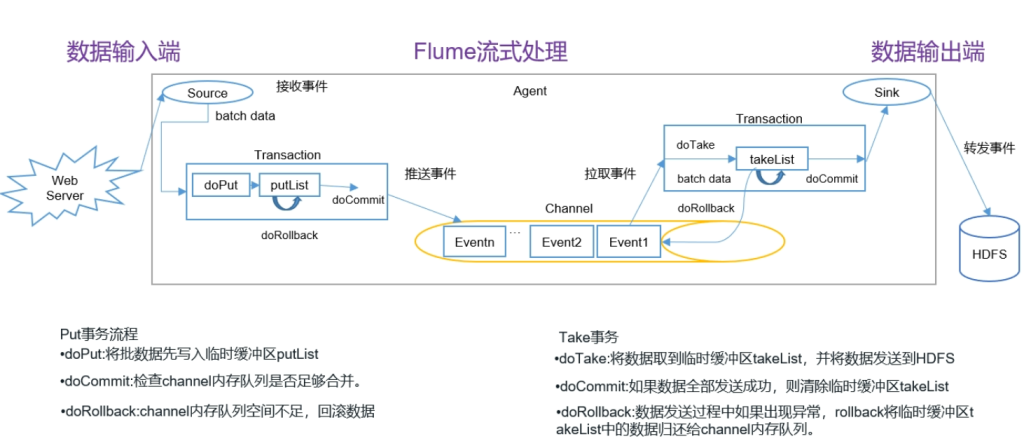
put事务流程:
- doPut将批数据先写入临时缓冲区putList
- doCommit检查channel内存队列是否足够合并
- doRollback:channel内存队列空间不足,回滚数据
Take事务
- doTake将数据取到临时缓冲区takeList,并将数据发送到HDFS
- doCommit如果数据发送成功,则清除临时缓冲区takeList
- doRollback数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存队列
Agent内部原理
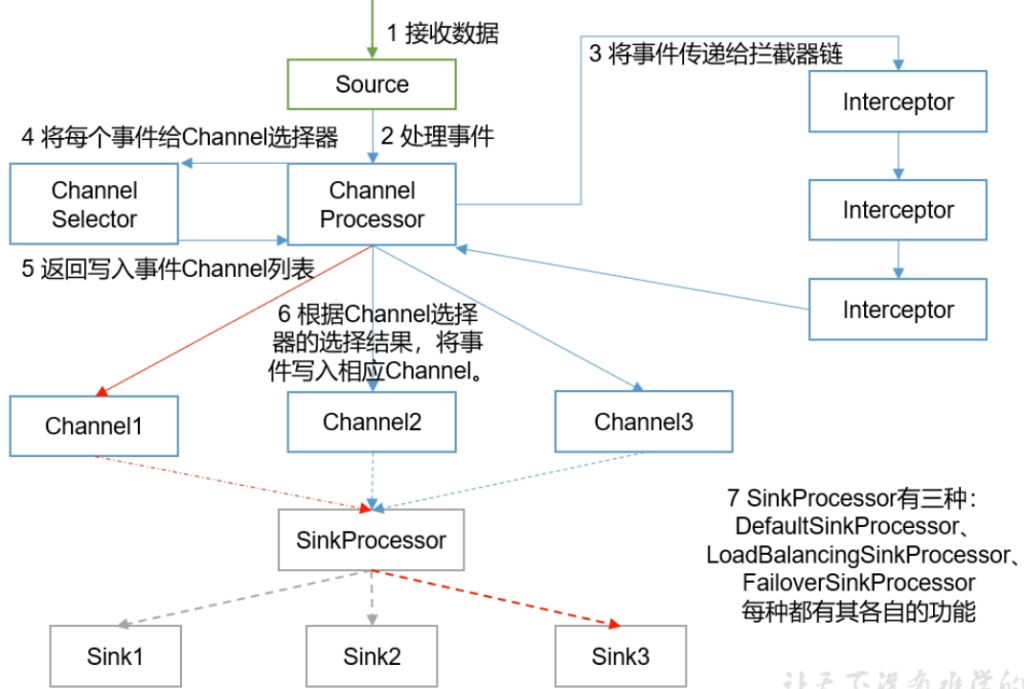
Channel Selectors有两种类型:
- Replicating Channel Selector(default)
- 将source过来的Events发往所有channel
- Multiplexing Channel Selector
- Multiplexing可以配置发往哪些Channel
SinkProcessor
- LoadBalancingSinkProcessor 负载均衡
- FailoverSinkProcessor 故障转移
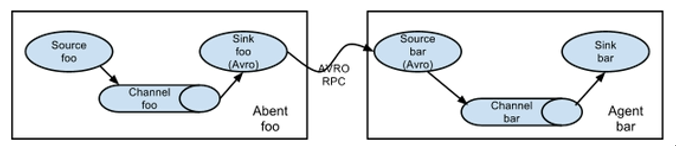
拓扑结构
- 简单串联
- 将多个flume串联起来,不建议过多的flume数量
- 复制和多路复用
- 支持将事件流向一个或多个目的地
- 这种模式可以将相同数据复制到多个channel中或者将不同数据分发到不同channel中,sink可以选择传送到不同的目的地
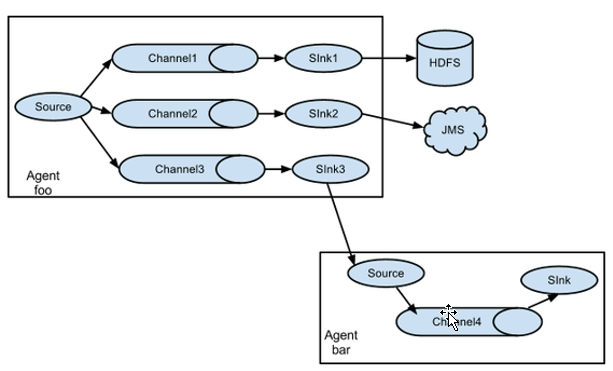
- 负载均衡和故障转移
- 将多个sink逻辑上分到一个sink组,sink组配合不同的SinkProcessor可以实现负载均衡和错误恢复的功能
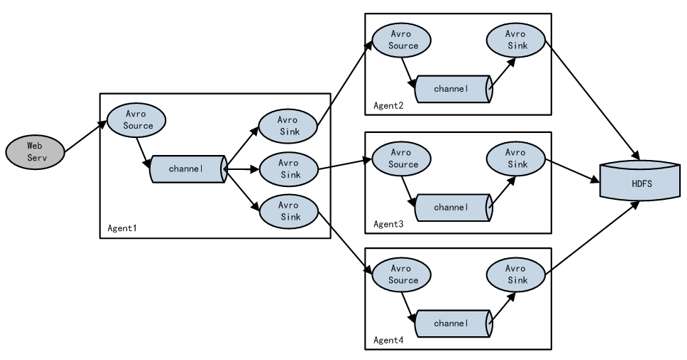
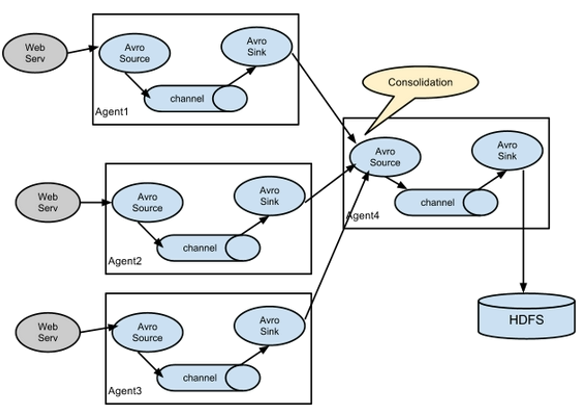
聚合
案例 复制和多路复用
- 需求
使用flume-1监控文件变动,flume-1将变动内容传递给flume-2,flume-2负责存储到HDFS,同时flume-1将变动内容传递到flume-3,flume-3负责输出到Local FileSystem
- 分析
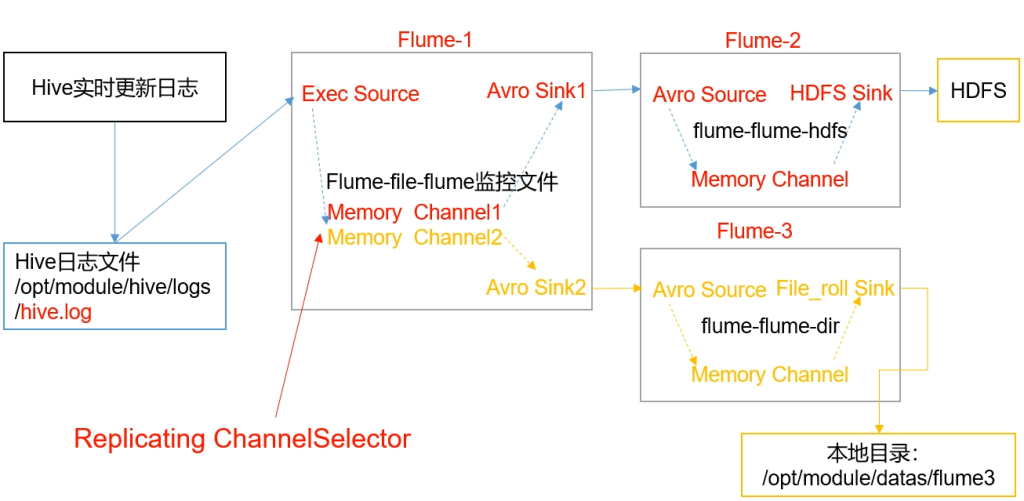
- avro
- source是服务端
- sink是客户端
- flume1.conf
# name
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /home/hadoop/test1/hive.log
a1.sources.r1.positionFile = /home/hadoop/position/position1.json
a1.sources.r1.selector.type = replicating
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop001
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop001
a1.sinks.k2.port = 4142
# bind
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2- flume2.conf
- 在操作hdfs时会提示没有操作文件权限,需要创建hdfs文件夹group1并赋予root权限
- hdfs dfs -mkdir /group1
- hdfs dfs -chown -R root /group1
# name
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop001
a2.sources.r1.port = 4141
# channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop001:8020/group1/%Y%m%d/%H
a2.sinks.k1.hdfs.filePrefix = log
a2.sinks.k1.hdfs.rollInterval = 30
a2.sinks.k1.hdfs.rollSize = 134217700
a2.sinks.k1.hdfs.rollCount = 0
a2.sinks.k1.hdfs.fileType = DataStream
a2.sinks.k1.hdfs.round = true
a2.sinks.k1.hdfs.roundValue = 1
a2.sinks.k1.hdfs.roundUnit = hour
a2.sinks.k1.hdfs.useLocalTimeStamp = true
# bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1flume3.conf
# name
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop001
a3.sources.r1.port = 4142
# sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /home/hadoop/test2
# channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# bind
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1案例2 故障转移
- 需求
使用flume1 监控一个端口 使sink组中的sink分别对接flume2 flume3 采用FailoverSinkProcessor
- 分析
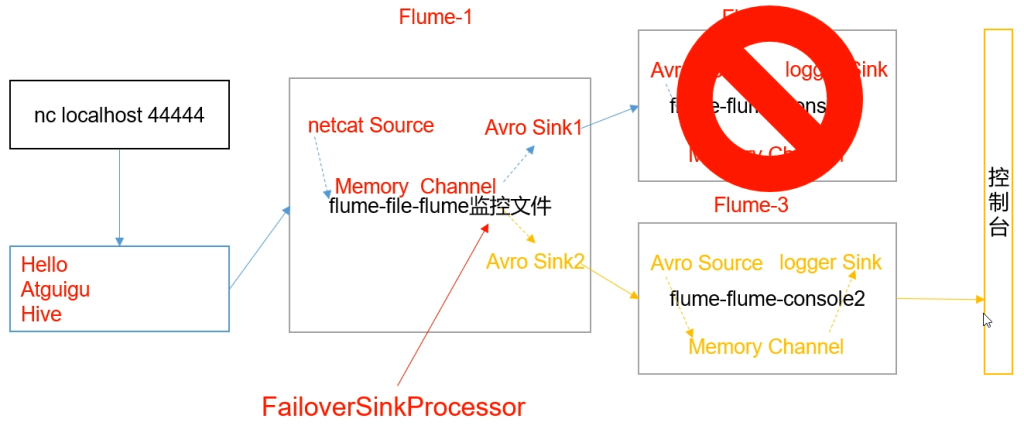
- flume1.conf
- 使用sinkgroups 来设置sink.processor 使用 failover
- priority 优先级
- maxpenalty 设置backoff退避超时时间,退避时间内会尝试再次连接,超时则不连接
# name
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
a1.sinkgroups = g1
# source
a1.sources.r1.type = netcat
a2.sources.r1.bind = localhost
a2.sources.r1.port = 44444
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop001
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop001
a1.sinks.k2.port = 4142
# sink group
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1flume2.conf
# name
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop001
a2.sources.r1.port = 4141
# sink
a2.sinks.k1.type = logger
# channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1flume3.conf
# name
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop001
a3.sources.r1.port = 4142
# sink
a3.sinks.k1.type = logger
# channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# bind
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1案例3 负载均衡
- 修改group2的flume1.conf
- a1.sinkgroups.g1.processor.type = load_balance
# name
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
a1.sinkgroups = g1
# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop001
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop001
a1.sinks.k2.port = 4142
# sink group
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1案例4 聚合
- 需求
hadoop001上的flume1监控文件hive.log
hadoop002上的flume2监控某一个端口的数据流
flume1与flume2将数据发送给hadoop003上的flume3,flume3将最终数据打印到控制台
- 分析
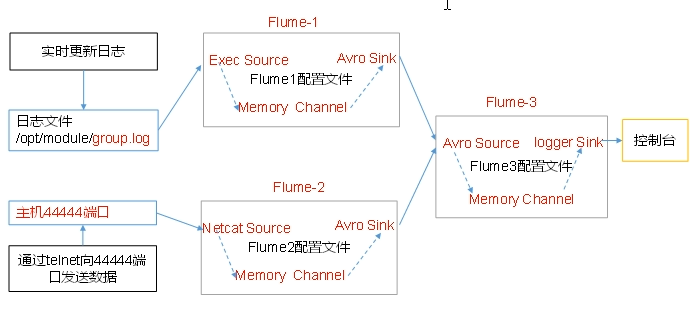
flume1.conf
# name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /home/hadoop/test1/hive.log
a1.sources.r1.positionFile = /home/hadoop/position/position2.json
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop003
a1.sinks.k1.port = 4141
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1flume2.conf
# name
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# source
a2.sources.r1.type = netcat
a2.sources.r1.bind = localhost
a2.sources.r1.port = 44444
# sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = hadoop003
a2.sinks.k1.port = 4142
# channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1flume3.conf
# name
a3.sources = r1 r2
a3.sinks = k1
a3.channels = c1
# source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop003
a3.sources.r1.port = 4141
a3.sources.r2.type = avro
a3.sources.r2.bind = hadoop003
a3.sources.r2.port = 4142
# sink
a3.sinks.k1.type = logger
# channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# bind
a3.sources.r1.channels = c1
a3.sources.r2.channels = c1
a3.sinks.k1.channel = c1案例5 多路复用 拦截器
- 需求
使用flume采集服务器上的日志,需按照日志类型的不同,将不同种类的日志发往不同的分析系统
以端口数据模拟日志,以数字(单个)和字母(单个)模拟不同类型的日志,我们需要定义interceptor区分数字和字母,将其分别发往不同的分析系统(channel)
- 分析
- 使用Flume拓扑结构中的Multiplexing Channel Selector,根据event中header的某个key值将不同的event发送到不同的channel中
- 使用拦截器Interceptor为不同类型的event的header中的key赋予不同的值
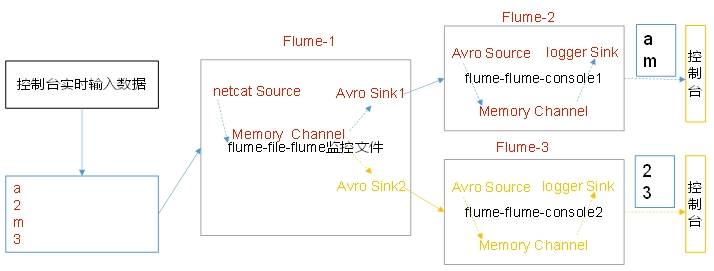
flume1.conf
# name
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# inerceptor
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.learn.flume.interceptors.TypeInterceptor$Builder
# channel selector
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = type
a1.sources.r1.selector.mapping.isWord = c1
a1.sources.r1.selector.mapping.notWord = c2
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop002
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop003
a1.sinks.k2.port = 4141
# bind
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2flume2.conf
# name
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop002
a2.sources.r1.port = 4141
# sink
a2.sinks.k1.type = logger
# channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1flume3.conf
# name
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop003
a3.sources.r1.port = 4141
# sink
a3.sinks.k1.type = logger
# channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# bind
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1