Blog
hadoop-04 hdfs
HDFS定义
- hdfs是一个文件系统,用于文件存储,通过目录树来定位文件
- 是分布式的
- 适合一次写入,多次读出的场景
优点:
- 高容错性
- 数据自动保存多个副本,通过增加副本的形式提高容错性
- 某个副本丢失后,可以自动恢复
- 适合处理大数据
- 数据规模:能够处理GB、TB、PB级别的数据
- 文件规模:能够处理百万规模以上的文件数量
- 可以构建在廉价的机器上,通过多副本机制,提高可靠性
缺点:
- 不适合低延迟数据访问
- 无法高效的对大量小文件进行存储
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息
- 一个文件块元数据大小:150字节
- NameNode的内存是有限的
- 小文件存储的寻址时间会超过读取时间
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息
- 不支持并发文件写入、文件随机修改
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据append(追加)不支持文件的随机修改
HDFS组成架构
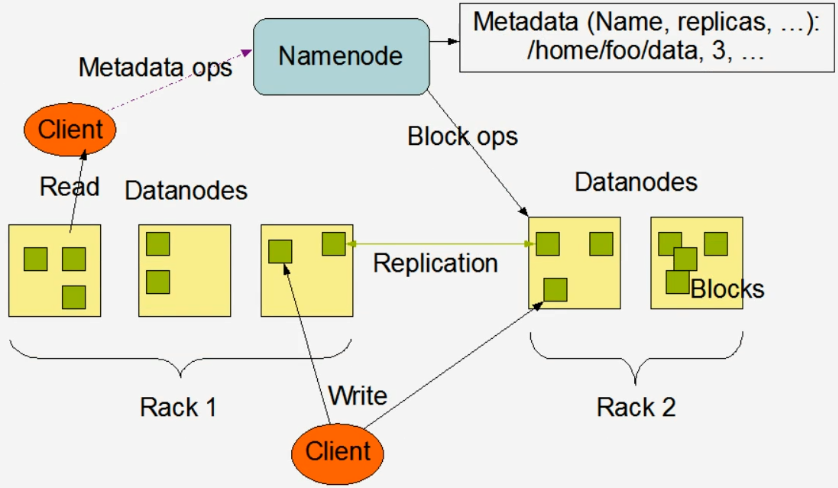
- NameNode(nn):
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块的映射信息
- 比如一个jar包200M 存储为一个128M 一个72M,128M存储节点不一定和72M文件存储节点一致
- DataNode:NameNode下达命令,DataNode执行实际操作
- 存储事件的数据块
- 执行数据块的读写操作
- Secondary NameNode:并非NameNode的热备,当NameNode挂掉的时候,并不能马上替换NameNode并提供服务
- 辅助NameNode 分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
- 在紧急情况下可以辅助恢复NameNode
- Client:客户端
- 文件切分。文件上传HDFS的时候Client将文件切分成一个一个的Block文件块,然后进行上传
- 按照NameNode的文件块来分割大小
- 与NameNode交互,获取文件的位置信息
- 与DataNode交互,读取或者写入数据
- Client提供一些命令来管理HDFS 比如NameNode格式化
- Client可以通过一些命令来访问HDFS,比如对HDFS增删改操作
- 文件切分。文件上传HDFS的时候Client将文件切分成一个一个的Block文件块,然后进行上传
修改文件块大小:hdfs-default.xml中dfs.blocksize默认134217728(128M)
hdfs块大小设置主要取决于磁盘传输速率
- 寻址时间为传输时间1% 最佳
- 比如寻址时间10ms 传输时间=10/0.01=1000ms=1s,一般磁盘速率100M/s 所以文件块大小128M比较合适