Blog
hadoop-07 hdfs的读写流程
hdfs写入数据流程
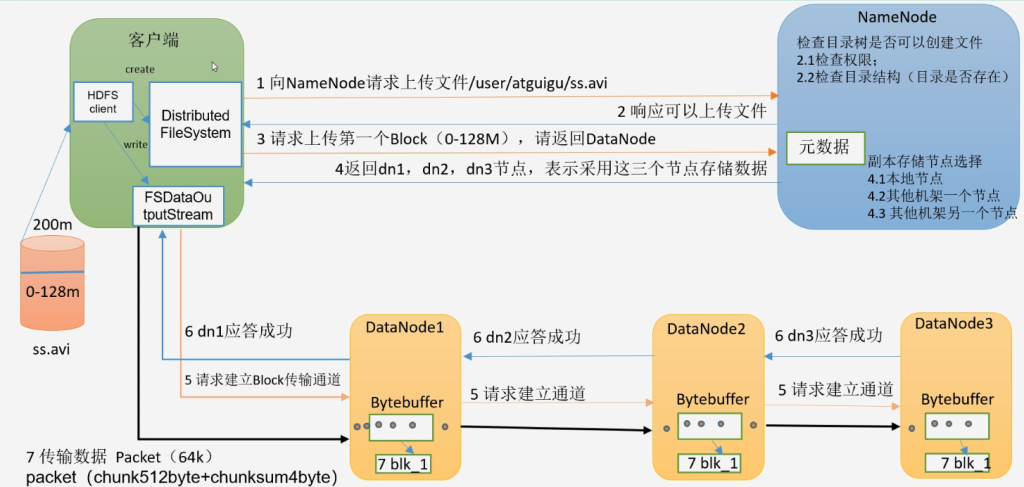
- 客户端创建一个分布式文件系统客户端
- 客户端向NameNode请求上传文件 /user/atguigu/ss.avi
- NameNode检查目录树是否可以创建文件
- 检查权限
- 检查目录结构(是否存在)
- NameNode检查目录树是否可以创建文件
- NameNode检查无误后给客户端返回响应可以上传文件
- 客户端请求上传第一个Block(0-128M),请返回哪些DataNode可以上传
- NameNode 存储副本选择
- 优先本地节点
- 负载均衡
- 其他机架一个节点
- 其他机架另一个节点
- NameNode 存储副本选择
- NameNode将可以存储的数据节点返回给客户端
- 客户端创建流向节点请求建立Block传输通道
- 先形成chunk当满足chunk512byte + chunksum4byte(校验位)大小为64k的时候就会形成一个packet对象进行传输
- 传输数据是packet 大小64k
- 传输过程中磁盘写一份,内存保存一份,然后从内存发给另外节点,保证传输速度
- 每个节点传输完毕后返回应答告知客户端传输完毕
- ack全部成功 缓存数据删除,ack失败则重新发送
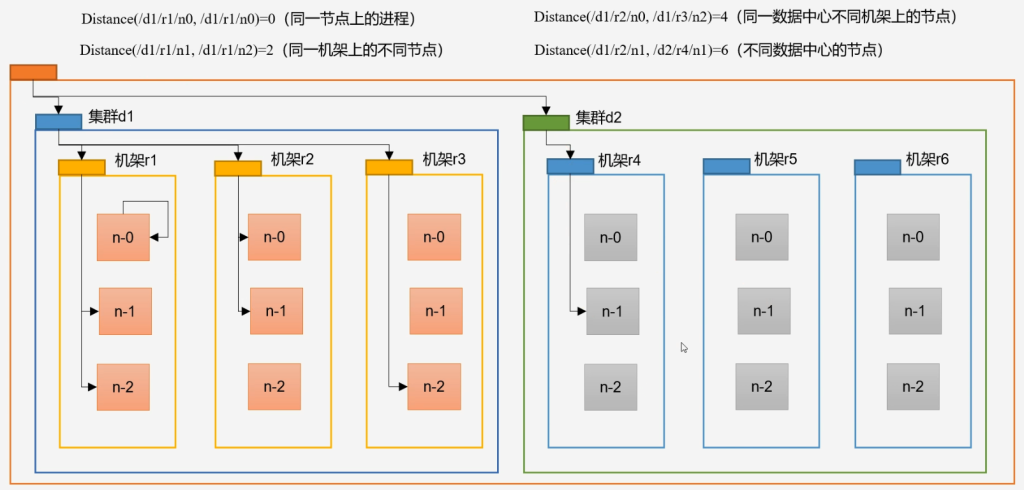
网络拓扑-节点举例计算
hdfs写数据过程中,namenode会选择距离上传数据最近距离的Datanode接收数据
节点距离:两个节点到达最近的共同祖先的距离总和
HDFS读数据流
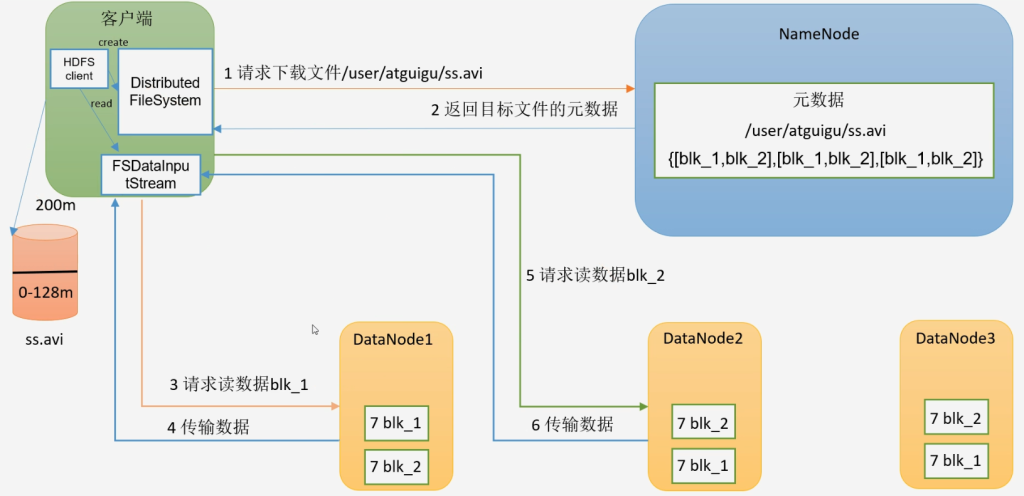
- 客户端创建分布式文件系统对象
- 客户端向NameNode请求下载文件
- NameNode 判断客户端是否有权限,并且判断要下载的文件是否存在
- 符合要求后NameNode把目标文件元数据返回给客户端
- 客户端创建流读取最近节点的数据
- 或者负载均衡分配节点的数据
- 先读取block1再读取block2