Blog
hadoop-09 DataNode工作机制
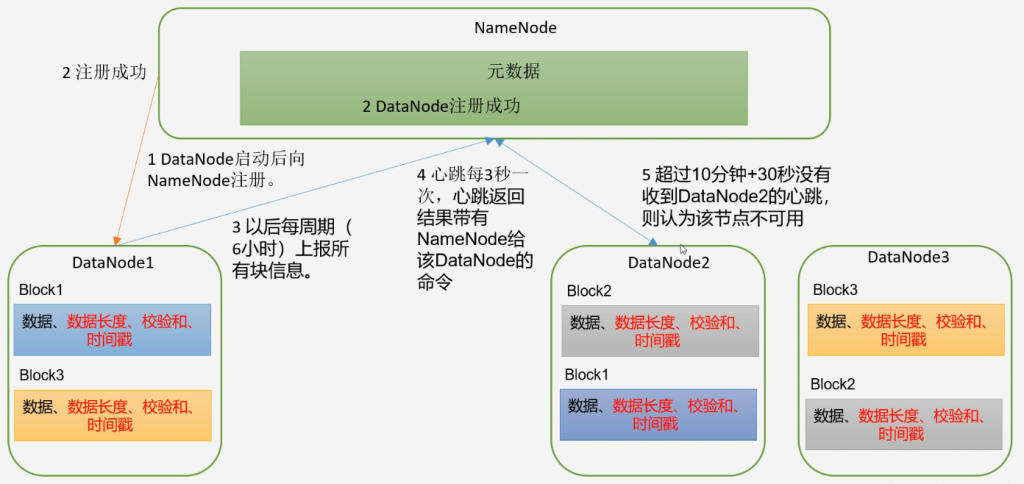
个人理解
- DataNode启动后向NameNode汇报块信息
- NameNode收到DataNode汇报后确定该DataNode还存活
- DataNode每隔6小时向NameNode汇报一次块信息
- 每隔3秒向NameNode发送一次心跳告知该DataNode还存活
- 如果超过10分钟+30秒还没有收到该DataNode的信息则认为该DataNode节点不可用
其他:
- 一个数据块在DataNode上以文件形式存储磁盘上,包括两个文件,一个是文件本身,一个是元数据(包括数据块的长度、数据块的校验以及时间戳)
- DataNode启动后向NameNode注册,通过后每隔6小时向NameNode报告所有的块信息
- dfs.blockreport.intervalMsec: 21600000
- DN扫描自己块信息列表时间,默认6小时:dfs.datanode.directoryscan.interval
- 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令,如复制块数据到另一台机器或者删除某个数据,如果超过10分钟没有收到某个DataNode的心跳则认为该节点不可用
数据完整性
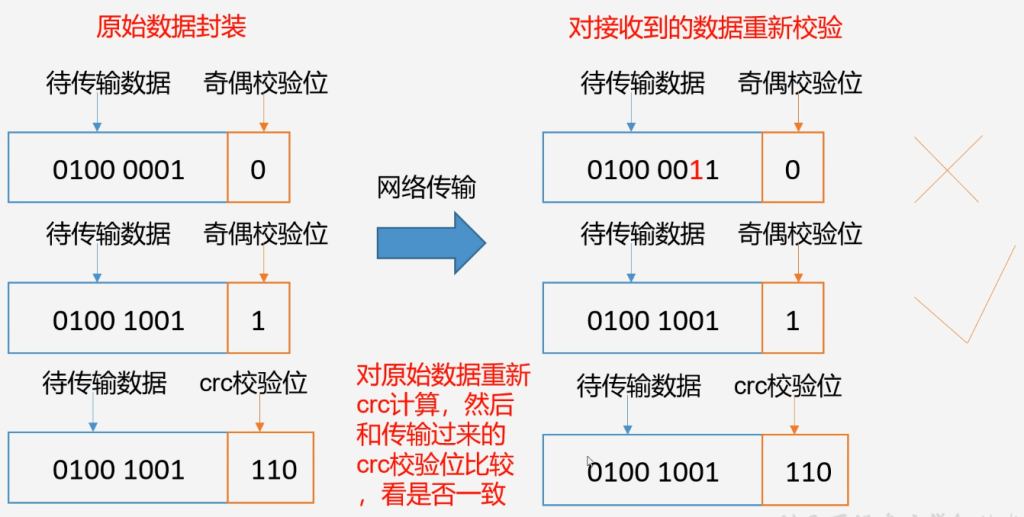
- 当DataNode读取Block的时候,会计算CheckSum
- 如果计算后的CheckSum与Block创建时的不一样,说明Block已经损坏
- 则Client读取其他DataNode上的Block副本
- 常见的校验算法crc(32),md5(128),sha1(160)
- DataNode在其文件创建后周期验证CheckSum
crc循环冗余校验在线计算:http://ip33.com/crc.html
crc后缀文件可以使用EditPlus打开 编码方式选择16进制查看器
掉线时限参数设置
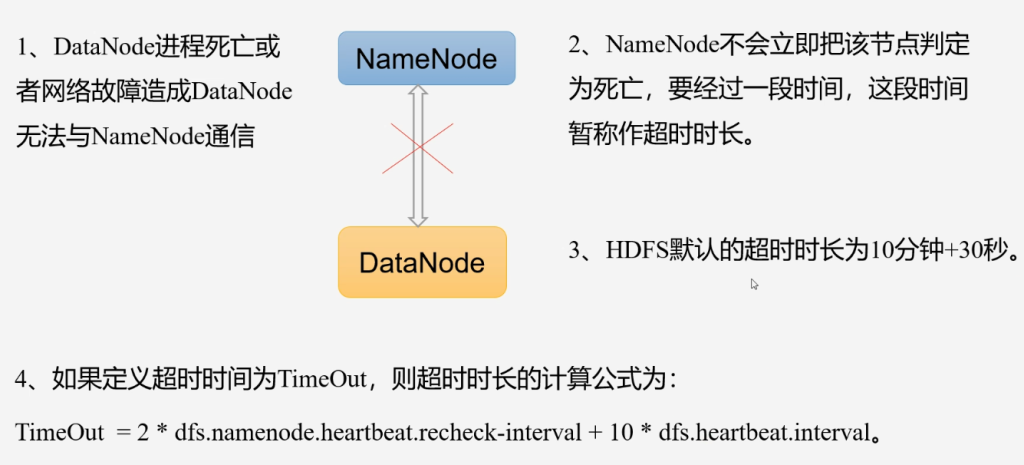
- dfs.namenode.heartbeat.recheck-interval:5分钟
- dfs.heartbeat.interval:3秒
超过10分钟+30秒

恢复DataNode
hdfs --daemon start datanode场景:4台DataNode节点设置副本数3
DN1 副本1
DN2 副本2
DN3 副本3
DN4
如果其中一台DataNode挂掉(DN3挂掉),然后再启动DN3,副本数有什么变化。
1、DN4会从DN1或DN2中复制一个副本,保证当前副本数3
2、当DN3再次启动后当前副本数变为4
3、集群会将多余的副本数删除,确保副本3。