Blog
hadoop-12 InputFormat
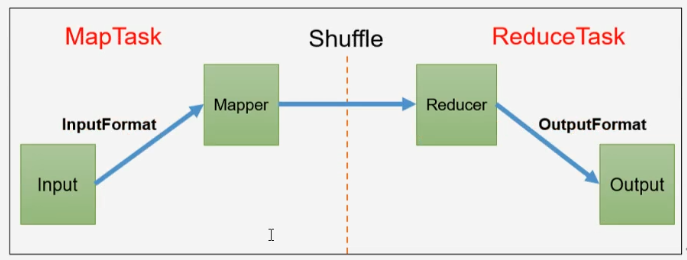
InputFormat数据输入
切片与MapTask并行度决定机制
- 问题引出
- MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度
- MapTask并行度决定机制
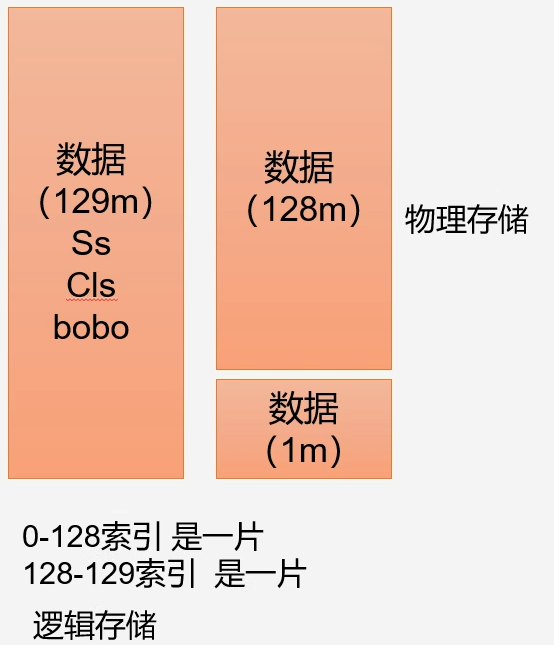
- 数据块:Block是HDFS物理上把数据块分成一块一块,数据块是HDFS存储数据单元
- 数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其分片存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask
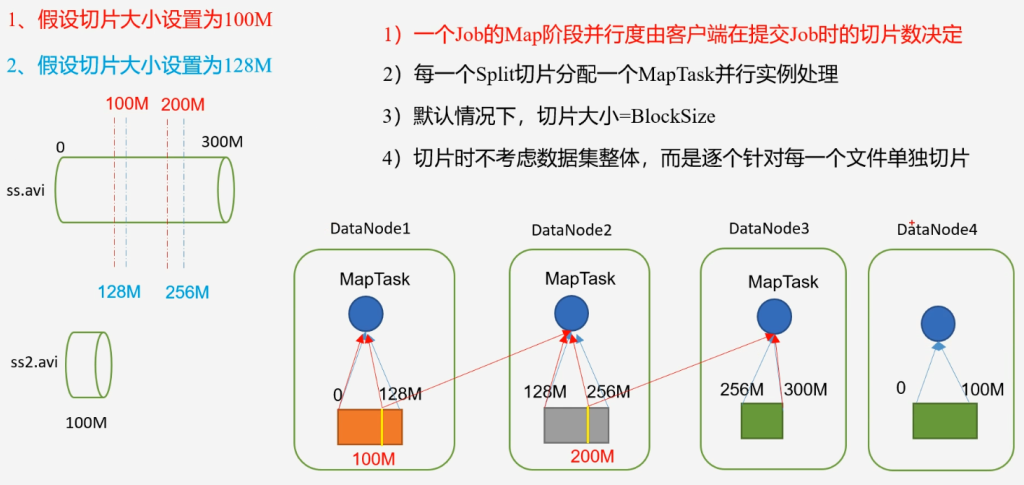
- 一个Job的Map阶段并行度由客户端在提交job时的切片数决定
- 每一个Split切片分配一个MapTask并行实例处理
- 默认情况下,切片大小=BlockSize
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
MapReduce job提交流程
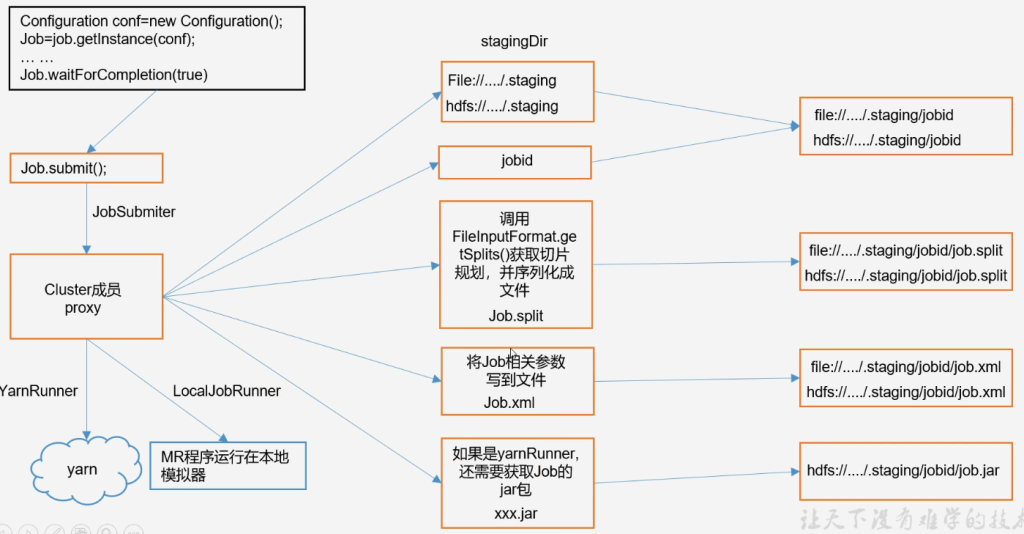
FileInputFormat切片源码解析
input.getSplits(job)

- 程序先找到你数据存储的目录
- 开始遍历处理(规划切片)目录下的每一个文件
- 遍历第一个文件ss.txt
- 获取文件大小fs.sizeOf(ss.txt)
- 计算切片大小
- computeSplitSize(Math.max(minSize, Math.min(maxSize, BlockSize)))
- 本地默认32M 集群默认128M
- maxSize和blockSize取最小值
- minSize和上一步结果取最大值
- computeSplitSize(Math.max(minSize, Math.min(maxSize, BlockSize)))
- 默认情况下切片大小=blockSize
- 开始切,形成第一个切片:ss.txt--0:128M,第二个切片ss.txt--128:256M,第三个切片ss.txt--256:300M。
- 每次切片时都要判断切换剩下的部分是否大于块的1.1倍,不大于1.1倍就划分为一块切片
- 将切片信息写到一个切片规划文件中
- 整个切片的核心过程在getSplit()方法中完成
- InputSplit只记录了切片的元数据信息,比如起始位置,长度及所在节点列表等。
- 只是逻辑记录切片信息,真正执行时MR任务
- 提交切片规划文件到YARN上,Yarn上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数
切片机制
- 简单的按照文件内容长度进行切片
- 切片大小,默认等于Block大小
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
切片大小设置
- maxsize(切片最大值):参数如果调的比blockSize小,则会让切片变小,而且就等于配置的这个参数的值
- minsize(切片最小值):参数调的比blocksize大,则可以让切片变得比blockSize还大
获取切片信息API
- 获取切片的文件名称
String name = inputSplit.getPath().getName();根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();TextInputFormat
- FileInputFormat实现类
- FileInput常见的接口实现类包括:
- TextInputFormat
- KeyValueTextInputFormat
- NLineInputFormat
- CombineTextInputFormat
- 自定义InputFormat
- TextInputFormat按行读取记录
- 键是存储该行在文件中起始字节偏移量,LongWriteable类型
- 值是这行的内容,不包括任何终止符(换行符和回车符)Text类型

- 前面的数字是偏移量,后面的值是行内容
CombineTextInputFormat切片机制
TextInputFormat不管文件多小,都是一个单独的切片,都会交给一个MapTask。这样如果有大量小文件,就会产生大量MapTask处理效率极其低下。
- CombineTextInputFormat用于小文件过多的场景,可以将多个小文件从逻辑上规划到一个切片中,这样多个小文件就可以交给一个MapTask处理
- 虚拟存储切片最大值设置
- CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); 4M
- 注意:虚拟存储切片最大值设置最好根绝实际小文件大小情况来设置具体的值
- 切片机制
- 生成切片过程包括:虚拟存储过程和切片过程

CombineTextInputFormat案例
- WordCountDriver .java
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 如果不设置InputFormat它默认使用TextInputFormat
job.setInputFormatClass(CombineTextInputFormat.class);
// 设置虚拟内存20M
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
FileInputFormat.setInputPaths(job, new Path("E:\\hadoop\\combineInput"));
FileOutputFormat.setOutputPath(job, new Path("E:\\hadoop\\combineOutput1"));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}- job.setInputFormatClass(CombineTextInputFormat.class);
- CombineTextInputFormat.setMaxInputSplitSize(job, 20971520); 20M