Blog
hadoop-24 hadoop生产调优
HDFS 核心参数
NameNode内存生产配置
每个文件块大概150byte
- namenode最小值1G,每增加1000000个block,增加1G内存
- datanode最小值4G,block数或者副本数升高,都应该调大datanode的值
- 一个datanode上的副本总数低于4000000调为4G,超过4000000每增加1000000增加1G
hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"NameNode心跳并发配置
namenode有一个工作线程池,用来处理不同DataNode的并发心跳,以及客户端并发的元数据操作
对于大集群或者有大量客户端的集群,通常需要增大该参数,默认值10
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>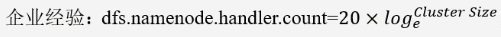
开启回收站配置
开始回收站功能可以将删除的文件不超时的情况下,恢复原数据,起到防止误删除、备份等作用
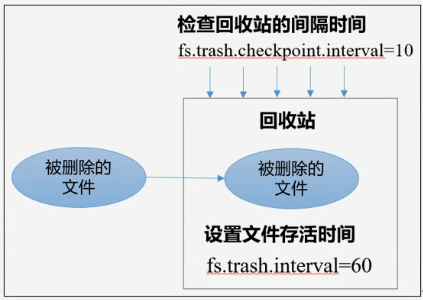
开启回收站功能参数说明
- 默认值fs.trash.interval = 0 表示禁用回收站,其他值表示设置文件的存活时间
- 默认值fs.trash.checkpoint.interval = 0 检查回收站的间隔时间,如果该值为0,则该值设置和fs.trash.interval的参数值相等
- 要求fs.checkpoint.interval <= fs.trash.interval
启用回收站
- 修改core-site.xml 配置垃圾回收时间为1分钟
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>- 查看回收站
- /user/atguigu/.Trash/...
- 通过网页上直接删除的文件不走回收站
- 通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = new Trash(conf)
trash.moveToTrash(path)- 只有在命令行使用hadoop fs -rm 命令删除的文件才会走 回收站
- 恢复数据可以使用-mv 将数据移出来
HDFS集群压测
100Mbps单位是bit,10M/s单位是byte;1byte=8bit,100Mbps/8=12.5M/s
开启简单http服务
python -m SimpleHTTPServer写测试
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 5 -fileSize 128MB-nrFiles:生成mapTask的数量,一般是集群中(CPU核数-1)

- Throughput=所有数据累加/总时间
- Average IO rate = 所有平均速度的平均值
结果分析:
由于一个副本在本地,所以该副本不参与测试
- 一共参与测试的文件:5个文件 * 2个副本 = 10个
- 压测后的速度3.84
- 实测速度:3.84M/s * 10个文件 = 38M/s
- 三台服务器的带宽: 12.5 + 12.5 + 12.5 = 37.5M/s
所有网络资源都已经用满,如果客户端不在集群节点,那就三个副本都参与计算
读测试
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 5 -fileSize 128MB
- 就近读取本地副本数据,不走网络
HDFS多目录
NameNode多目录配置
namenode本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
具体配置如下:
- hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
</property>- 因为每台服务器节点的磁盘情况不同,所以这个配置配完之后,可以选择不分发
- 停止集群,删除三台节点data和logs中所有数据
rm -rf data/ logs/格式化集群并启动
hdfs namenode -format
start-dfs.shDataNode多目录配置
DataNode可以配置成多个目录,每个目录存储的数据不一样(数据不是副本)

具体配置如下:hdfs-site,xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>磁盘数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘,刚加载的硬盘没有数据,可以执行磁盘数据均衡命令
- 生成均衡计划
hdfs diskbalancer -plan hadoop103执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.jsonHDFS集群扩容即缩容
添加白名单
- 白名单:表示在白名单的主机IP地址可以,用来存储数据
- 企业中配置白名单,可以尽量防止黑客恶意访问攻击
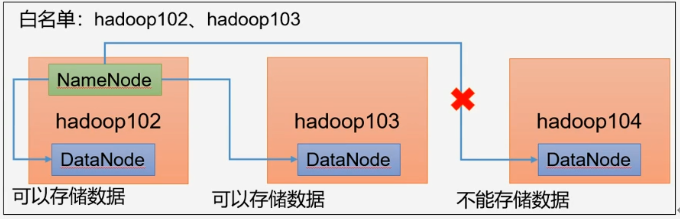
配置白名单步骤如下:
- 在namenode节点的hadoop/etc/hadoop目录下分别创建whitelist和blacklist文件
- 创建白名单,添加hadoop102和hadoop103节点
vim whitelist
# 添加
hadoop102
hadoop103- 创建黑名单 touch blacklist
- 配置hdfs -site.xml
<!-- 白名单 -->
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property>
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>- 分发配置文件
- xsync whitelist
- 第一次添加白名单必须重启集群,不是第一次,只需要刷新namenode节点即可
myhadoop.sh stop
myhadoop.sh start- 104不再被当做存储数据副本节点
- 白名单添加hadoop104
- 刷新namenode
- 刷新所有namenode datanode节点
hdfs dfsadmin -refreshNodes添加新的数据节点
环境准备:
- 在hadoop100上再克隆一台主机hadoop105
- 修改ip地址和主机名称
- 将102下的hadoop和jdk拷贝到hadoop105
scp -r /opt/module/hadoop-3.1.3/ atguigu@hadoop105:/opt/module
scp -r /opt/module/jdk1.8.0_212 atguigu@hadoop105:/opt/module 拷贝环境变量
sudo scp /etc/profile.d/myenv.sh root@hadoop105:/etc/profile.d/- 保留JDK和HADOOP_HOME环境变量
- source /etc/profile
- ssh无密访问
- hadoop102(namenode) -> hadoop105
- hadoop102(resourcemanager) -> hadoop105
- ssh-copy-id hadoop105
- 删除hadoop105中hadoop文件夹下的data和logs文件夹
rm -rf data/ logs/启动hadoop105上的datanode和nodemanager
hdfs --daemon start datanode
yarn --daemon start nodemanager- 如果未配置白名单则立即生效
- 配置白名单
- whitelist增加hadoop105并分发
- hdfs dfsadmin -refreshNodes
节点间数据均衡
- 开启数据均衡命令
- threshold 代表集群中各个节点的磁盘空间利用率相差不超过10%
sbin/start-balancer.sh threshold 10通知数据均衡命令
sbin/stop-balancer.sh - 由于HDFS需要单独启动单独的Rebalance Server 来执行Rebanlance操作,所以尽量不要在NamoNode上执行start-balancer.sh 尽可能找一台空闲的机器
退役一个数据节点
把当前节点副本复制给其他节点,停止该节点存储数据
blacklist添加hadoop105
- hdfs-site.xml
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>- 分发配置文件
- 第一次添加黑名单必须重启集群。不是第一次则只需要刷新NameNode节点
hdfs dfsadmin -refreshNodes
手动停止hadoop105上datanode和nodemanager进程
hdfs --daemon stop datanode
yarn --daemon stop nodemanager如果数据不均衡,可以用命令实现集群的再平衡
sbin/start-balancer.sh threshold 10查看数据块存储信息
hdfs fsck /input -files -blocks -locationsHDFS故障排除
NameNode故障处理
namenode进程挂了并且存储数据也丢失了,如何恢复namenode
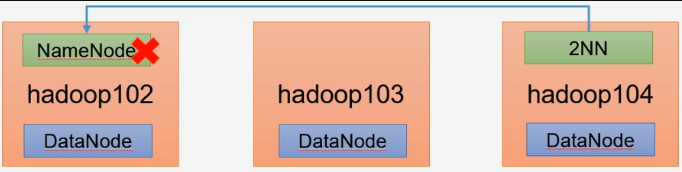
- kill -9 namenode进程
- 删除hadoop/data/dfs/name/下所有namenode数据
- 切换到hadoop104(secondarynamenode)节点 查看2NN信息
/opt/module/hadoop-3.1.3/data/dfs/namesecondary复制2NN数据到hadoop102 NN节点
scp -r atguigu@hadoop104:/opt/module/hadoop-3.1.3/data/dfs/namesecondary/* /opt/module/hadoop-3.1.3/data/dfs/name- 生成环境一般不用这个方法 ,使用HA高可用 两个NN
集群安全模式和磁盘修复
安全模式:文件系统只接受读数据请求,而不接受删除、修改等变更请求
进入安全模式场景:
- namenode在加载镜像文件和编辑日志处于安全模式
- 集群启动中
- namenode在接收datanode注册时,处于安全模式
退出安全模式条件:
- dfs.namenode.safemode.min.datanodes
- 最小可用datanode数量,默认0
- dfs.namenode.safemode.threshold-pct
- 副本数达到最小要求的block占系统总block百分百,默认0.999f (只允许丢一个块)
- dfs.namenode.safemode.extension
- 稳定时间,默认30秒
基本语法
- 查看安全模式
- hdfs dfsadmin -safemode get
- 进入安全模式状态
- hdfs dfsadmin -safemode enter
- 离开安全模式
- hdfs dfsadmin -safemode leave
- 等待安全模式
- hdfs dfsadmin -safemode wait
磁盘修复
删除三个节点上两个块数据
cd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1230679643-192.168.10.102-1618410754513/current/finalized/subdir0/subdir0
rm -rf rm -rf blk_1073741829 rm -rf blk_1073741829.meta rm -rf blk_1073741828 rm -rf blk_1073741828.meta- 重启集群(一直安全模式)
- 离开安全模式命令
- hdfs dfsadmin -safemode leave
- 接着告知文件块错误
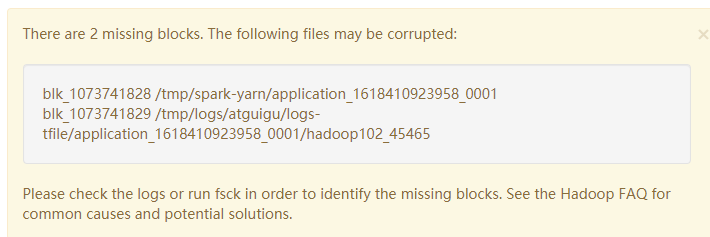
- 按照上面提示删除对应路径文件即可
慢磁盘查找
- 心跳时间长
- fio命令,测试磁盘读写性能
sudo yum install -y fio
# 顺序读
sudo fio -filename=/home/atguigu/test.log -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r
# 顺序写
sudo fio -filename=/home/atguigu/test.log -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r- -rw=randwrite随机写
- -rw=randrw混合随机速写
- -rwmixread=70
小文件归档
大量小文件会耗尽NameNode中的大部分内存,存储小文件所需要的磁盘容量和数据块的大小无关
解决存储小文件办法之一:
- HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,运行文件进行透明的访问

- 启动yarn
- 归档文件
- 把/input陌路里所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/output路径下
hadoop archive -archiveName input.har -p /input /output查看归档
hadoop fs -ls /output/input.har
# 查看真实归档信息
hadoop fs -ls har:///output/input.har- 解归档文件
- 将归档文件中words.txt拷贝到根目录
hadoop fs -cp har:///output/input.har/words /HDFS集群迁移
apache和apache集群间数据拷贝
- scp实现两个远程主机之间文件复制
- 采用distcp命令实现两个hadoop集群之间的递归数据复制
bin/hadoop distcp hdfs://hadoop102:8020/xxx/xx.txt hdfs://hadoop105:8020/xxx/xx.txt apache和CDH集群间数据拷贝
MapReduce生成经验
mapreduce跑的慢的原因
- 计算机性能
- I/O操作优化
- 数据倾斜,多个map发送到一个reduce
- map运行时间太长,导致reduce等待太久
- 小文件过多
MapReduce常用参数调优
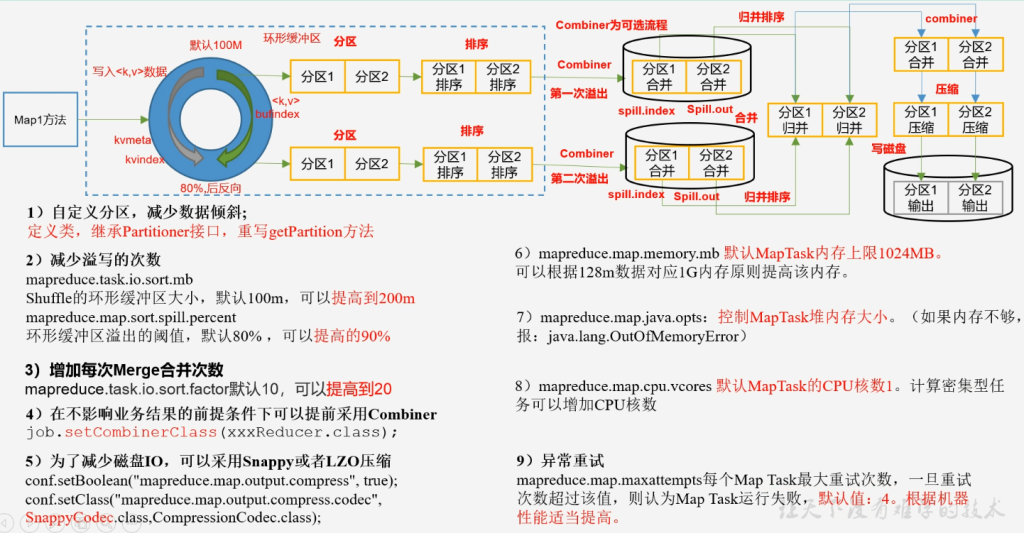
MapTask阶段调优:
- 自定义分区,减少数据倾斜
- 定义类,继承Partitioner接口,重写getPartition方法
- 减少溢写的次数
- mapreduce.task.io.sort.mb
- Shuffle的环形缓冲区大小,默认100m,可以提高到200m
- mapreduce.map.sort.spill.percent
- 环形缓冲区溢出的阈值,默认80% 可以提高到90%
- 增加每次Merge合并次数
- mapreduce.task.io.sort.factor默认10,可以提高到20
- 在不影响业务结果的前提条件下,可以提前采用Combiner
- job,setCombinerClass(xxxReducer.class)
- 为了减少磁盘IO,可以采用Snappy或者LZO压缩
- conf.setBoolean("mapreduce.map.output.compress", true)
- conf.setClass("mapreduce.map.output.compress.codec", SnappyCodec.class, CompressionCodec.class)
- mapreduce.map.memory.mb 默认MapTask内存上线1024MB
- 可以根据128M数据对应1G内存原则提高该内存
- mapreduce.map.java.opts:控制MapTask堆内存大小,如果内存不够,报OutOfMemoryError
- mapreduce.map.cpu.vcores 默认MapTask的CPU核数1,计算密集型任务可以增加CPU核数
- 异常重试
- mapreduce.map.maxattempts每个MapTask最大重试次数,一旦重试次数超过该值,则认为MapTask运行失败,默认值:4 ,根据机器性能适当提高。
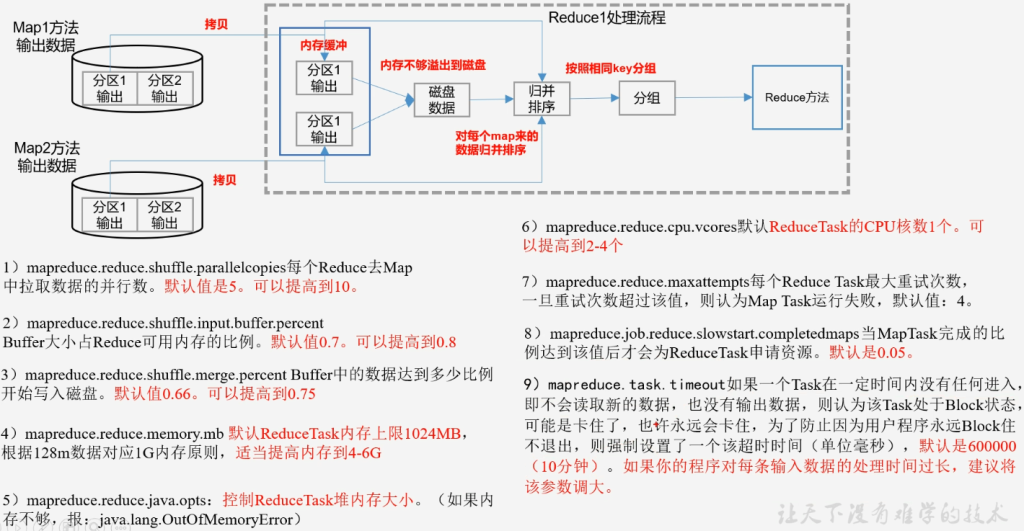
Reduce阶段调优:
- mapreduce.reduce,shuffle.parallelcopies
- 每个Reduce去Map中拉取数据的并行数,默认5,可以提高到10
- mapreduce.reduce.shuffle.input.buffer.percent
- Buffer大小占Reduce可用内存的比例,默认0.7,可以提高到0.8
- mapreduce.reduce.shuffle.merge.merge.percent
- Buffer中的数据达到多少比例开始写入磁盘,默认0.66,可以提高到0.75
- mapreduce.reduce.memory.mb默认ReduceTask内存上线1024MB,根据128M数据对应1G内存原则,适当提高内存到4-6G
- mapreduce.reduce.java.opts:控制ReduceTask堆内存大小,不够则包OM错误
- mapreduce.reduce.cpu.vcores默认ReduceTask的CPU核数1个,可以提高到2-4个
- mapreduce.reduce.maxattempts每个Reduce Task最大重试次数,默认4
- mapreduce.job.reduce.slowstart.completedmaps
- 当MapTask完成的比例达到该值后会为ReduceTask申请资源,默认0.05
- mapreduce.task.timeout
- 如果一个Task一定时间内没有任何进入也没有输出数据则认为该Task处于Block状态,为防止用户程序永远Block卡住不退出,则设置一个超时时间,默认600000(10分钟)
- 如果程序对每条输入数据的处理时间过长,建议将该参数调大
减少数据倾斜的方法
- 首先检查是否空值过多,造成的数据倾斜
- 生产环境,可以直接过滤掉空值
- 如果想保留空值,就自定义分区,将空值加随机数打散,最后再二次聚合
- 能在map阶段提前处理,最好在map阶段处理,如Combiner,MapJoin
- 设置多个reduce个数