Blog
hive-08 函数
系统内置函数
- 查看系统自带的函数
- show functions
- 显示自带的函数的用法
- desc function upper
- 详细显示自带的函数的用法
- desc function extend upper
- 函数类型
- UDF 一进一出
- UDAF 多进一出
- UDTF 一进多出
常用内置函数
NVL空字段赋值
给值为NULL的数据赋值
它的格式是NVL(col, default_value),如果col为NULL则NVL函数返回default_value的值,否则返回col 的值
CASE WHEN THEN ELSE END
- 准备数据
悟空 A 男
大海 A 男
宋宋 B 男
凤姐 A 女
婷姐 A 女
婷婷 B 女建表语句
CREATE TABLE emp_sex(
name string,
dept_id string,
sex string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
LOAD DATA INPATH '/test/emp_sex.txt' INTO TABLE emp_sex;HQL
SELECT dept_id,
SUM(CASE sex WHEN '男' THEN 1 ELSE 0 END) maleCount,
-- 使用if 函数实现
SUM(if(sex = '女', 1, 0)) femaleCount
FROM emp_sex
GROUP BY dept_id;多列变一列
- CONCAT(string A/col, string B/col...)
- 返回输入字符串连接后的结果,支持任意个输入字符串
SELECT CONCAT('a', '-', 'b', '-', 'c');- CONCAT_WS(separator, str1, str2...)
- 特殊形式的CONCAT()
- 分隔符可以使与剩余参数一样的字符串
- 如果分隔符是NULL,返回值也将为NULL
- 这个函数会跳过分隔符参数后的任何NULL和空字符串
SELECT CONCAT_WS('-', 'a', 'b', 'c');- COLLECT_SET(col) 聚合函数
- 函数只接受基本数据类型
- 将某个字段的值进行去除汇总,产生Array类型字段
- COLLECT_LIST(col) 不去重
- 统计每个部门 男、女的姓名
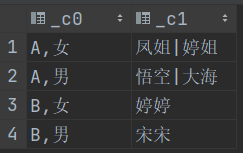
SELECT CONCAT_WS(',', dept_id, sex), CONCAT_WS('|', COLLECT_SET(name))
FROM emp_sex
GROUP BY dept_id, sex;一行变多行
- EXPLODE(col)
- 将hive一列中复杂的array或者map结构拆分成多行
- LATERAL VIEW 侧写表
- 用法 LATERAL VIEW udtf(expression) tableAlias AS columnAlias
- 解释 用于和split,explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合
- 保持炸裂字段与原表字段保持关联
- split(col, 'separator')
- 分割字符串 返回数组
- 准备数据
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难HQL
SELECT name, category_name
FROM movie
LATERAL VIEW explode(split(category, ',')) info as category_name;窗口函数
- over()
- 指定分析函数工作的数据窗口大小
- 这个数据窗口大小可能会随着行的变化而变化
说明:以下参数写在over()函数内部,限定开窗范围 ROWS BETWEEN ... AND ...
- CURRENT ROW 当前行
- n PRECEDING 往前n行数据
- n FOLLOWING 往后n行数据
- UNBOUNDED 起点
- UNBOUNDED PRECEDING 表示从前面的启点
- UNBOUNDED FOLLOWING 表示到后面的终点
以下函数使用在over()函数 左侧
- LAG(col, n, default_val) 往前第n行数据
- LEAD(col, n, default_val) 往后第n行数据
- NTILE(n) 把有序窗口的行发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号,n必须为int类型
- FIRST_VALUE 窗口里取第一条
- LAST_VALUE 窗口里取最后一条
准备数据
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94建表语句
CREATE TABLE order_info
(
name string,
orderdate date,
cost int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';获取2017年4月份购买过的顾客及总人数
SELECT name, count(1) over ()
FROM order_info
WHERE month(orderdate) = 4
GROUP BY name;- over 在group by查询之后生效
- 计算顾客的购买明细及月购买总额
SELECT name,
orderdate,
cost,
sum(cost) over (PARTITION BY month(orderdate))
FROM order_info;将每个顾客的cost按照日期进行累加
SELECT name,
orderdate,
cost,
-- 有分区、有排序、有指定窗口范围
sum(cost) over (PARTITION BY name ORDER BY orderdate rows BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM order_info;- 如果有分区、有排序没有窗口范围,则默认窗口使用RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
- 计算当前行的前一行 后一行和当前行的和
SELECT name,
orderdate,
cost,
sum(cost) over (PARTITION BY name ORDER BY orderdate ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
FROM order_info;计算起点到当前行的前一行
SELECT name,
orderdate,
cost,
sum(cost) over (PARTITION BY name ORDER BY orderdate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING)
FROM order_info;按照日期进行累加
SELECT name,
orderdate,
cost,
sum(cost) over (ORDER BY orderdate)
FROM order_info;- 如果排序时有相同的排序值
- 会同时计算相同字段的值
1 1
2 3
3 9
3 9
4 13
5 18查询每个用户上次的购买时间
SELECT name,
orderdate,
cost,
LAG(orderdate, 1, NULL) over (PARTITION BY name ORDER BY orderdate)
FROM order_info;- 也可以 LAG(orderdate, 1, orderdate) 默认值使用自己数据
- LAG 把上面数据往下拿 LEAD 把后面数据往前拿
- 查询前20%时间的订单信息
SELECT name,
orderdate,
cost
FROM (
SELECT name,
orderdate,
cost,
NTILE(5) OVER (ORDER BY orderdate) groupId
FROM order_info
) a
WHERE a.groupId = 1;- RANK()
- 排序相同时会重复,总数不会变
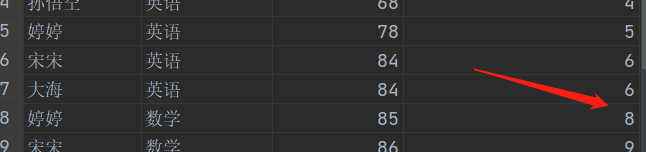
- DENSE_RANK()
- 排序相同时会重复,总数会减少
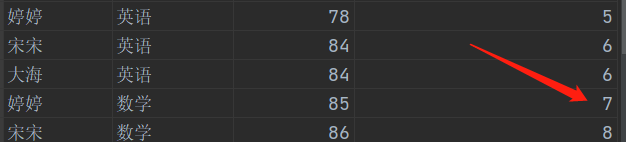
- ROW_NUMBER()
- 会根据顺序计算
- 计算每科前三的成绩
SELECT *
FROM (
SELECT name, class, score, ROW_NUMBER() over (PARTITION BY class ORDER BY score DESC ) no
FROM stu
)a
WHERE a.no <= 3常用日期函数
- unix_timestamp
- 返回当前或者指定时间的时间戳
- 第二个参数可以指定日期时间格式
- SELECT UNIX_TIMESTAMP(CURRENT_DATE());
- from_unixtime
- 将时间戳转为日期格式
- SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(CURRENT_DATE()));
- current_date
- 当前日期
- SELECT CURRENT_DATE();
- current_timestamp
- 当前日期时间
- SELECT CURRENT_TIMESTAMP();
- to_date
- 抽取日期部分
- SELECT TO_DATE(CURRENT_TIMESTAMP());
- year
- 获取年
- month
- 获取月
- day
- 获取日
- hour
- 获取时
- minute
- 获取分
- second
- 获取秒
- weekofyear
- 当前时间是一年中的第几周
- SELECT weekofyear(current_date());
- dayofmonth
- 当前时间是一个月中的第几天
- SELECT dayofweek(current_date());
- months_between
- 两个日期间的月份
- SELECT months_between('2021-01-01', current_date());
- add_months
- 日期加减月
- SELECT add_months(current_date, 1);
- datediff
- 两个日期相差的天数
- SELECT datediff('2021-05-01', current_date());
- date_add
- 日期加天数
- SELECT date_add(current_date(), 1);
- date_sub
- 日期减天数
- last_day
- 日期当前月的最后一天
- SELECT last_day(current_date());
- date_format
- 格式化日期
- SELECT date_format(current_date(), 'yyyy/MM/dd');
常用取整函数
- round
- 四舍五入、
- ceil
- 向上取整
- floor
- 向下取整
常用字符串操作函数
- upper
- 转大写
- lower
- 转小写
- length
- 长度
- trim
- 前后去空格
- lpad
- 向左补齐,到指定长度
- SELECT lpad("abc", 10, '0');
- rpad
- 向右补齐,到指定长度
- regexp_replace
- 使用正则表达式匹配目标字符串,匹配成功后替换
- SELECT REGEXP_REPLACE('2021/01/01', '/', '-');
集合操作
- size
- 集合中元素的个数
- map_keys
- 返回map中的key
- map_values
- 返回map中的value
- array_contains
- 判断array中是否包含某个元素
- SELECT array_contains(split("hello,world", ","), "hello");
- sort_array
- 将array中的元素排序
维度分析
- grouping sets
准备数据
1001,zhangsan,male,10
1002,lisi,female,10
1003,banzhang,female,20
1004,haiwang,male,20
1005,banhua,male,30
1006,shehuiyang,female,30计算总人数、每个部门人数、各部门不同性别人数
- group by 部门, 性别
SELECT deptno, sex, count(*)
FROM staff
GROUP BY deptno, sex GROUPING SETS ((deptno, sex), deptno, sex, ());作业:
- wordcount
- 数据
hello,spark
hello,hive
hadoop,hiveHQL
SELECT a.word, count(1) num
FROM (
SELECT explode(split(line, ',')) word
FROM word_count
) a
GROUP BY word;SELECT word, count(word)
FROM word_count LATERAL VIEW explode(split(line, ',')) tmp as word
GROUP BY word;自定义函数分类
- UDF (user defined function)
- 一进一出
- UDTF (user defined table generating functions)
- 一进多出
- lateral view explode()
- UDAF (user defined aggregation function)
- 聚集函数
- 多进一出
编程步骤
- 继承hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF- 实现类中的抽象方法
- 在hive的命令行窗口创建函数
- 添加jar
- 创建function
add jar linux_jar_path
create [temporary] function [dbname.]function_name AS class_name;在hive命令行窗口删除函数
drop [temporary] function [if exists] [dbname.] function_namehdfs路径
create [temporary] function [dbname.]function_name AS class_name using jar hdfs_path/xxx.jar;自定义UDF函数
导入依赖pom.xml
- dependency 声明并引入依赖
- 放入所有子模块都需要的包 比如日志log4j
- dependencyManagement 声明但不引入依赖 父项目pom.xml控制版本号
- 子项目导入依赖无需填写版本号
- 不是所有模块都依赖的包
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>MyLenUDF
public class MyLenUDF extends GenericUDF {
// 校验数据参数:个数
// objectInspector 类型校验器
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 1) {
throw new UDFArgumentException("参数个数不为1");
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
// 处理数据
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
// arguments udf函数接收的数据,比如upper('hello') 这里的'hello' 就是arguments元素
// 1.取出输入数据
String input = arguments[0].get().toString();
// 2.判断输入数据是否为null
if (input == null) {
return 0;
}
// 3.返回输入数据的长度
return input.length();
}
// 执行计划 使用
@Override
public String getDisplayString(String[] children) {
return "";
}
}- 打包成jar包上传到服务器
- 将jar包添加到hive的classpath
add jar /linux_path/myudf.jar创建临时函数与开发好的java class关联
create temporary function my_len as "com.learn.udf.MyLenUDF"- 永久函数
- 使用函数时要添加注册函数时候的库名
create function test.my_len as "com.fosung.bigdata.udf.MyLenUDF" using jar "hdfs://hadoop001:8020/hive-udf/MapToJsonUDF-1.0-SNAPSHOT.jar";自定义UDTF函数
public class MyUDTF extends GenericUDTF {
private ArrayList<String> outPutList = new ArrayList<String>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// count(*) 输出数据的默认列名 可以被别名覆盖
List<String> fieldNames = new ArrayList<>();
// 添加返回列名word
fieldNames.add("word");
// 输出数据的类型
// explode可以接收map 输出key列和value列
List<ObjectInspector> fieldOIs = new ArrayList<>();
// 添加返回word字段string类型
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
// 最终返回值
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
/**
* 处理输入数据:hello,world
* 输出数据:
* hello
* world
*/
@Override
public void process(Object[] args) throws HiveException {
// args 表示使用函数传入的值 比如 min(1, 2)这里的1,2就是args的元素
// 1 取出输入数据
String input = args[0].toString();
// 2 按照逗号分割
String[] words = input.split(",");
// 3 遍历数据写出
for (String word : words) {
// 清空集合
outPutList.clear();
// 将数据放入集合
// 因为initialize方法定义返回数据fieldOIs类型是ArrayList<string>()
outPutList.add(word);
// 输出数据
forward(outPutList);
}
}
// 收尾方法
@Override
public void close() throws HiveException {
}
}- forward每调用一次就,写出一行数据
返回两列UDTF
a,b:c,d -> a b
c d
public class MyUDTF2 extends GenericUDTF {
private final ArrayList<String> outPutList = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// 输出两列 列名
List<String> fieldNames = new ArrayList<>();
fieldNames.add("col1");
fieldNames.add("col2");
// 输出两列的类型检查器
List<ObjectInspector> fieldOIs = new ArrayList<>();
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
// a,b:c,d
String input = args[0].toString();
String[] group1 = input.split(":");
for (String s : group1) {
String[] words = s.split(",");
outPutList.clear();
// 添加两列值
outPutList.add(words[0]);
outPutList.add(words[1]);
// 输出一行数据 两列
forward(outPutList);
}
}
@Override
public void close() throws HiveException {
}
}如果关联原字段 使用侧写表lateral view ...as后面要跟两个别名