Blog
hive-09 压缩和存储
Hadoop压缩配置
MR支持的压缩编码
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
| DEFLATE | DEFLATE | .deflate | 否 |
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .bz2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
为了支持多种压缩/解压算法,Hadoop引入了编码/解码器
| 压缩格式 | 对应的编码/解码器 |
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.lzopCpdec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩参数配
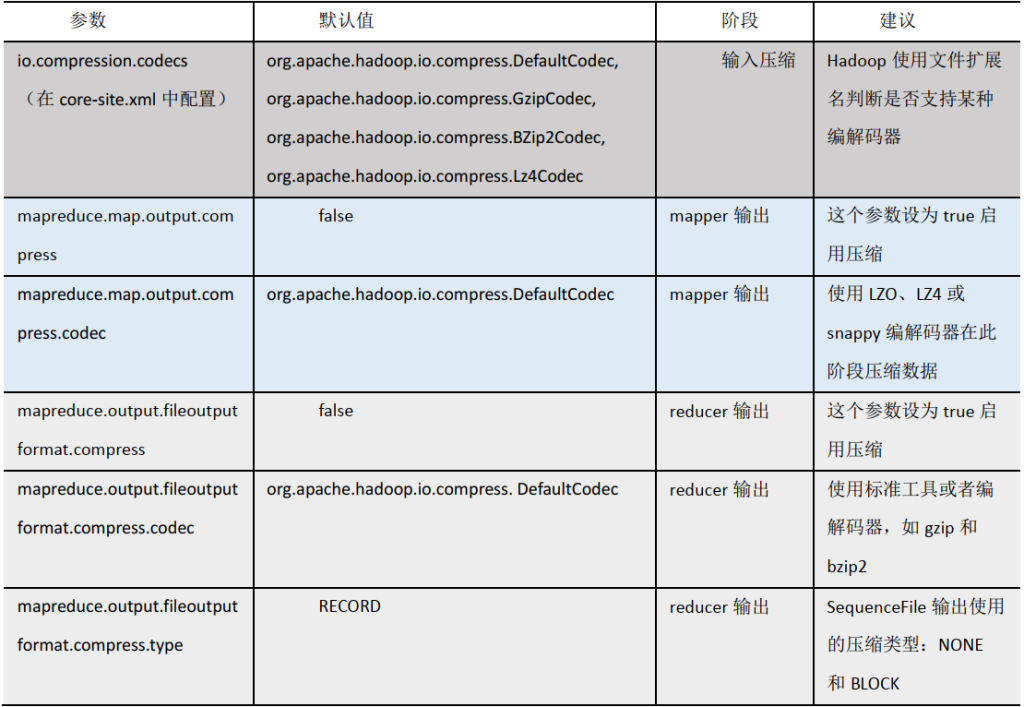
开启Map输出阶段压缩(MR引擎)
中间过程压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量
- 开启hive中间传输数据压缩功能
- set hive.exec.compress.intermediate=true;
- 开启mapreduce中map输出压缩功能
- set mapreduce.map.output.compress=true
- 设置mapreduce中map输出数据的压缩方式
- set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
- 执行查询语句
- select count(ename) name from emp;
开启Reduce输出阶段压缩
最终输出压缩
当hive将输出写入到表中时,输出内容同样可以进行压缩。
- 开启hive最终输出数据压缩功能
- set hive.exec.compress.output=true
- 开启mapreduce最终输出数据压缩
- set mapreduce.output.fileoutputformat.compress=true
- 设置mapreduce最终数据输出压缩方式
- set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
- 设置mapreduce最终数据输出压缩为块压缩
- set mapreduce.output.fileoutputformat.compress.type=BLOCK
- 测试
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
INSERT OVERWRITE DIRECTORY '/test/res'
SELECT *
FROM emp DISTRIBUTE BY deptno SORT BY empno DESC;文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE、SEQUENCEFILE、ORC、PARQUET
列式存储和行式存储
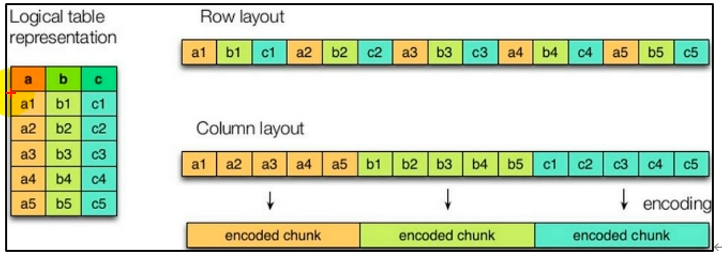
extFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大,可结合Gzip和bzip2使用,但Gzip格式hive不会对数据进行切分,从而无法对数据进行并行操作
Orc格式
Orc:Optimized Row Columnar 是Hive1.0引入的新的存储格式
每个Orc由1和或多个stripe组成
每个stripe一般为HDFS的块大小
每一个stripe包含多条记录
这些记录按照列进行独立存储
每个stripe有三部分组成:index Data,Row Data,Stripe Footer
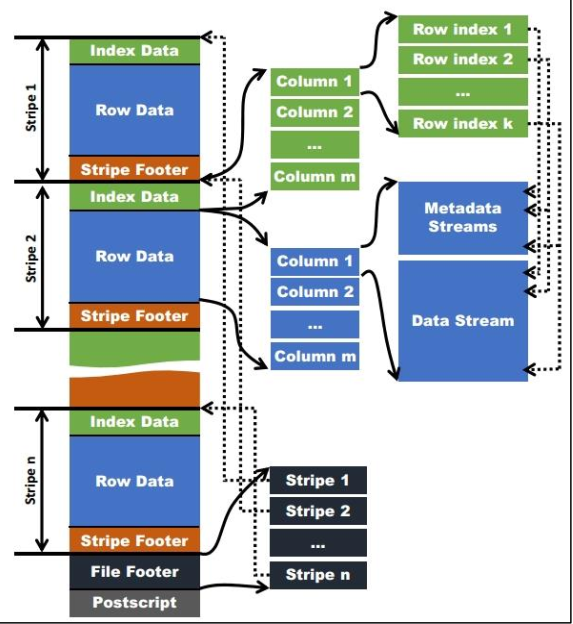
- index Data:一个轻量级的index,默认是每隔1w行做一个索引,这里做的索引应该只是记录某行的各个字段在RowData中的offset
- Row Data:存的是具体的数据,先去部分行,然后对这些行按列进行存储,对每个列进行编码,分成多个Stream来存储
- Stripe Footer:存的是各个Stream的类型,长度等信息
- 每个文件有一个FileFooter 这里面存的是每个Stripe的行数,每个Column的数据类型等信息
- 每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等
- 在读取文件是会seek到文件尾部读PostScript从里面解析到FileFooter的长度,再读FileFooter,从里面解析到各个Striper信息,再读各个Striper,即从后往前读
Parquet格式
spark默认文件格式parquet,解析做了特殊处理,运行效率会更高
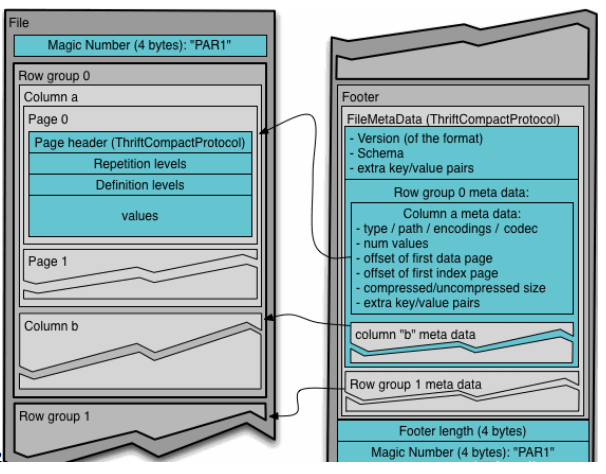
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件包括该文件的数据和元数据
Parquet格式文件是自解析的
- 行组Row Group 每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念
- 列块Column Chunk 在一个行组中每一列保存在一个列块中
- 行组中的所有列连续的存储在这个行组文件中
- 一个列块中的值都是相同类型的
- 不同的列块可能使用不同算法进行压缩
- 页 page 每一个列块划分为多个页
- 一个页就是最小的编码单位
- 在同一个列块的不同页可能使用不同的编码方式
通常情况下,在存储Parquet数据的时候回按照Block大小设置行组的大小,由于一般情况下,每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度
创建一个ZLIB压缩的ORC存储方式
CREATE TABLE log_orc_zlib(
name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS orc
TBLPROPERTIES('orc.compress'='ZLIB')创建一个SNAPPY压缩的parquet存储方式
CREATE TABLE log_parquet_snappy(
name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS parquet
TBLPROPERTIES('parquet.compress'='snappy')推荐ORC结合snappy