Blog
paimon-05 DML
插入数据

- part_spec
- 可选,指定分区的键值对列表,多个逗号分隔,可以使用类型文字如:date'2022-01-01'
- column_list
- 可选,指定以逗号分隔的字段列表
- 包括除静态分区外的所有字段
- value_expr
- 指定要插入的值
- 可以插入显式指定的值或NULL 必须使用逗号分隔句子中的每个值
- flink目前不支持直接使用NULL 因此需要将NULL转换为实际数据类型值
- CAST(NULL AS STRING)
- 不能将另一个表的可为空的列插入到一个表的非空列中
INSERT INTO A key1 SELECT COALESCE(key2, 非空 表达式) FROM B- A表key1时not null B表key2时nullable
paimon支持在sink阶段通过partition和bucket对数据进行shuffle
覆盖数据
覆盖数据支支持batch模式
默认情况下,流式读取将忽略INSERT OVERWRITE生成的提交
如果想读取OVERWRITE的提交可以配置streaming-read-overwrite
RESET 'execution.checkpointing.interval';
SET 'execution.runtime-mode' = 'batch';覆盖未分区的表
INSERT OVERWRITE test VALUES(1, 1, 'pay', '2023-01-01', '2');- 覆盖分区表
- 对于分区表paimon默认的覆盖模式时动态分区覆盖
- 即只删除insert overwrite数据中出现的分区
- 可以配置动态分区来更改它
- 对于分区表paimon默认的覆盖模式时动态分区覆盖
- 清空数据
- 可以使用INSERT OVERWRITE 通过插入空值来清除表(关闭动态分区覆盖)
INSERT OVERWRITE test_p/*+ OPTIONS('dynamic-partition-overwrite'='false') */ SELECT * FROM test_p WHERE false;更新数据
目前paimon在flink 1.17及后续版本支持UPDATE更新记录
可以在flink批处理模式下执行UPDATE
只有主键表支持此功能
MergeEngine需要deduplicate或partial-update才能支持此功能
- deduplicate 保持最新行
- partial-update部分列更新(宽表部分字段更新)
- aggregate 主键相同的其他列聚合
UPDATE test SET item_id = 3, behavior='pv' WHERE user_id=4;删除数据
- 只有写入默认设置为change-log的表支持此功能
- 有主键默认就是change-log
- 如果表有主键MergeEngine需要为deduplicate
DELETE FROM test WHERE user_id = 4;Merge Into
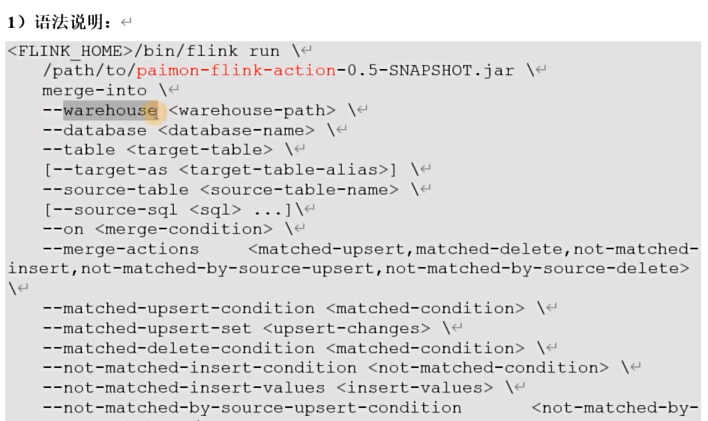
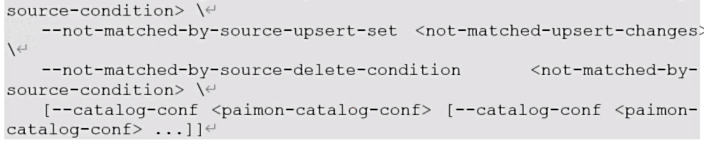
实现行级更新,只有主键表支持此功能
该操作不会产生UPDATE_BEFORE 因此不建议设置’changelog-producer‘='input'
merge-into操作使用upsert而不是update,也就是如果该行存在则执行更新,否则执行插入


paimon-flink-action-0.5-20230829.001915-123.jar 不需要放到lib/目录,可以放到flink/opt/目录下
USE catalog hive_catalog;
CREATE DATABASE test;
use test;
CREATE TABLE ws1 (
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
);
INSERT INTO ws1 VALUES(1,1,1),(2,2,2),(3,3,3);
CREATE TABLE ws_t (
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
);
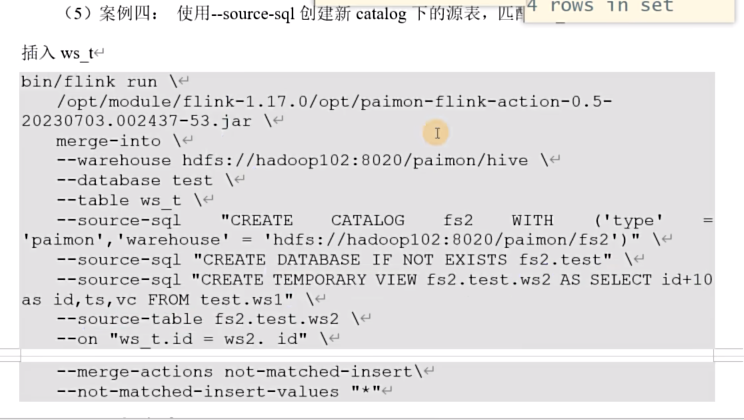
INSERT INTO ws_t VALUES(2,2,2),(3,3,3),(4,4,4),(5,5,5);案例一:ws_t与ws_1匹配id,将ws_t中ts>2的vc改为10 ts <=2的删除
bin/flink run \
opt/paimon-flink-action-0.5-20230829.001915-123.jar \
merge-into \
--warehouse hdfs://mycluster/paimon/hive \
--database test \
--table ws_t \
--source-table test.ws1 \
--on "ws_t.id=ws1.id" \
--merge-actions matched-upsert,matched-delete \
--matched-upsert-condition "ws_t.ts > 2" \
--matched-upsert-set "vc = 10" \
--matched-delete-condition "ws_t.ts <= 2"案例二:ws_t与ws1匹配id,匹配上的将ws_t中vc加10es中没有匹配上的插入到ws_t中
bin/flink run \
opt/paimon-flink-action-0.5-20230829.001915-123.jar \
merge-into \
--warehouse hdfs://mycluster/paimon/hive \
--database test \
--table ws_t \
--source-table test.ws1 \
--on "ws_t.id=ws1.id" \
--merge-actions matched-upsert,not-matched-insert \
--matched-upsert-set "vc = ws_t.vc + 10" \
--not-matched-insert-values "*"案例三:ws_t与ws1匹配id,ws_t中没有匹配上的,ts大于4则vc加20 ts=4则删除
bin/flink run \
opt/paimon-flink-action-0.5-20230829.001915-123.jar \
merge-into \
--warehouse hdfs://mycluster/paimon/hive \
--database test \
--table ws_t \
--source-table test.ws1 \
--on "ws_t.id=ws1.id" \
--merge-actions not-matched-by-source-upsert,not-matched-by-source-delete \
--not-matched-by-source-upsert-condition "ws_t.ts>4" \
--not-matched-by-source-upsert-set "vc = ws_t.vc + 20" \
--not-matched-by-source-delete-condition "ws_t.ts=4"