Blog
paimon-09 CDC集成
paimon支持多种通过模式演化将数据提取到paimon表中的方法,意味着添加的列会实时同步到paimon表中,并且不会因此重新启动同步作业。
目前支持以下同步方式:
- mysql同步表:将mysql中的一张或多张表同步到一张paimon表中
- mysql同步数据库:将整个mysql数据库同步到一个paimon数据库中
- api同步表:将自定义DataStream输入同步到一种paimon表中
- kafka同步表:将一个kafka topic的表同步到一张paimon表中
- kafka同步数据库:将一个包含多表的kafka主题同步到一个paimon数据库中
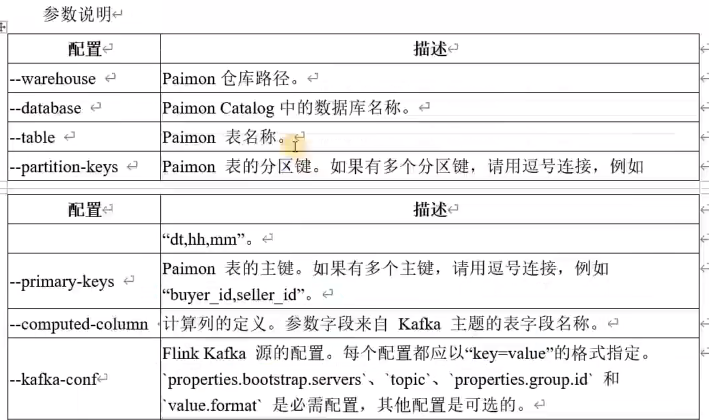
Mysql
添加flink cdc连接器
cp flink-sql-connector-mysql-cdc-2.4.1.jar /data/flink/-1.17.1/lib/重启yarn-session和sql-client
同步表
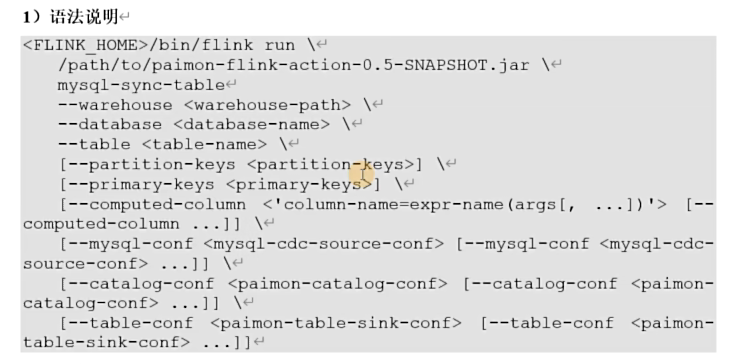
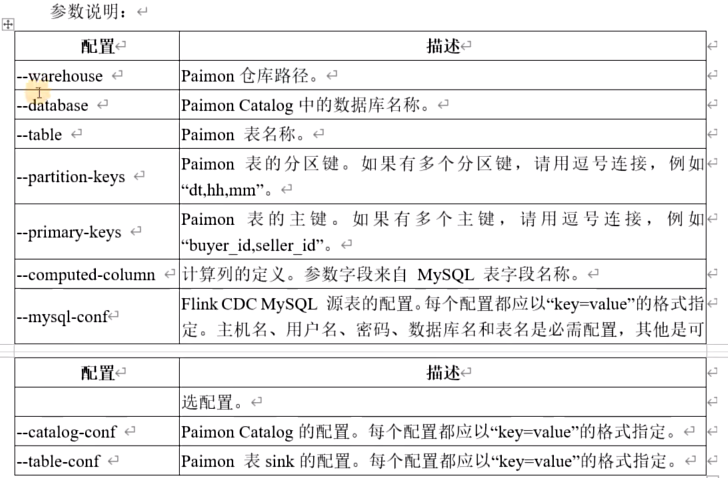
如果指定paimon表不存在,此操作将自动创建该表,其schema将从所有指定的mysql表派生。
如果paimon表已存在,则其schema将与所有指定mysql表的schema进行比较
示例:
bin/flink run \
opt/paimon-flink-action-0.5-20230829.001915-123.jar \
mysql-sync-table \
--warehouse hdfs://mycluster/paimon/hive \
--database test \
--table order_info_cdc \
--primary-keys id \
--mysql-conf hostname=hadoop001 \
--mysql-conf username=root \
--mysql-conf password=000000 \
--mysql-conf database-name=tms \
--mysql-conf table-name='order_info' \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://hadoop001:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-sink sink.parallelism=4同步数据库
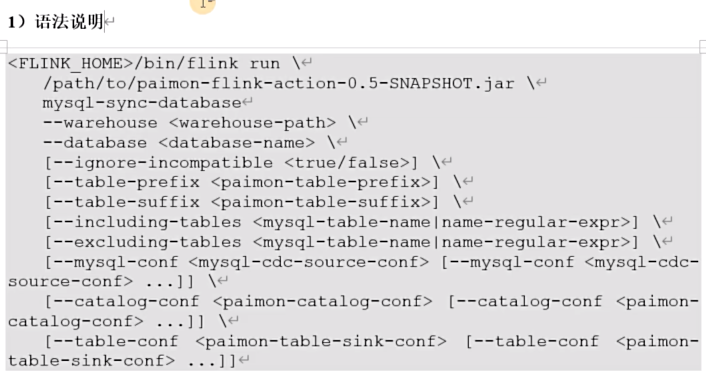
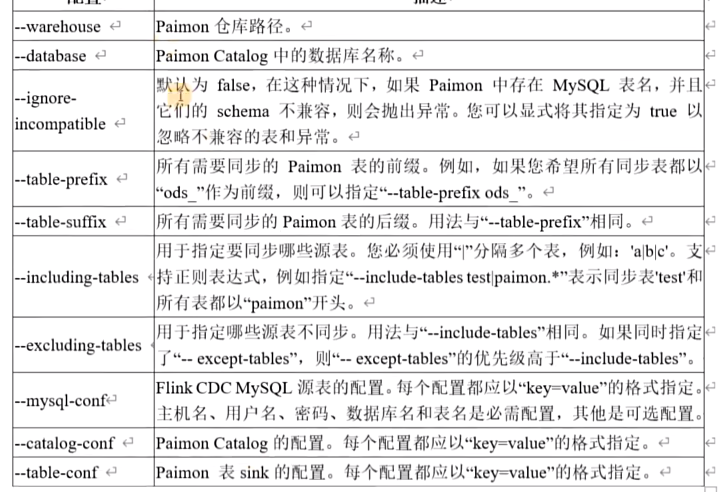
只有具有主键的表才被同步
示例:
bin/flink run \
opt/paimon-flink-action-0.5-20230829.001915-123.jar \
mysql-sync-database \
--warehouse hdfs://mycluster/paimon/hive \
--database test \
--table-prefix "ods_" \
--table-suffix "_cdc" \
--mysql-conf hostname=hadoop001 \
--mysql-conf username=root \
--mysql-conf password=000000 \
--mysql-conf database-name=tms \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://hadoop001:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-sink sink.parallelism=4 \
--including-tables 'user_info|order_info|base_region_info'同步数据库下新添加的表
可以通过从作业的先前快照中恢复并从而重用作业的现有状态来实现这一点。
恢复的作业首先对新添加的表进行快照,然后自动从之前的位置继续去读变更日志
从以前的快照恢复并添加信标进行同步的命令如下:
bin/flink run \
--fromSavepoint savepointPath \
opt/paimon-flink-action-0.5-20230829.001915-123.jar \
mysql-sync-database \
--warehouse hdfs://mycluster/paimon/hive \
--database test \
--table-prefix "ods_" \
--table-suffix "_cdc" \
--mysql-conf hostname=hadoop001 \
--mysql-conf username=root \
--mysql-conf password=000000 \
--mysql-conf database-name=tms \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://hadoop001:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-sink sink.parallelism=4 \
--including-tables 'user_info|order_info|base_region_info|新表1|新表2'Kafka
flink提供了集中kafka cdc格式:canal-json、debezium-json、0gg-json、maxwell-json
如果kafka主题中消息是使用的cdc工具从一个数据库捕获的更改事件 则可以使用paimon kafka cdc,解析后的insert update delete消息会写入到paimon表中
添加kafka连接器
cp flink-sql-connector-kafka-1.17.1.jar /data/flink/-1.17.1/lib/重启yarn-session集群和sql-client


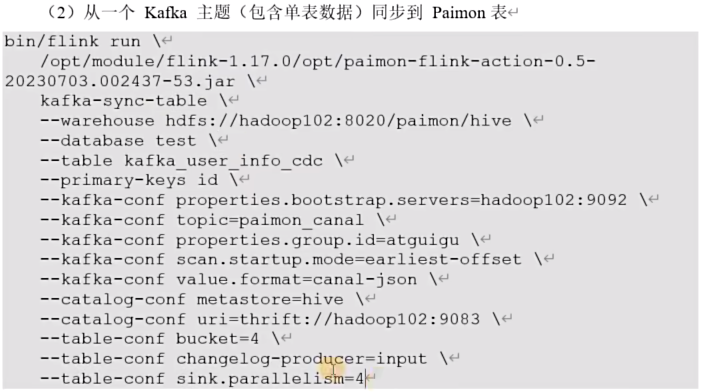
同步数据库

一个topic存多个表的cdc数据
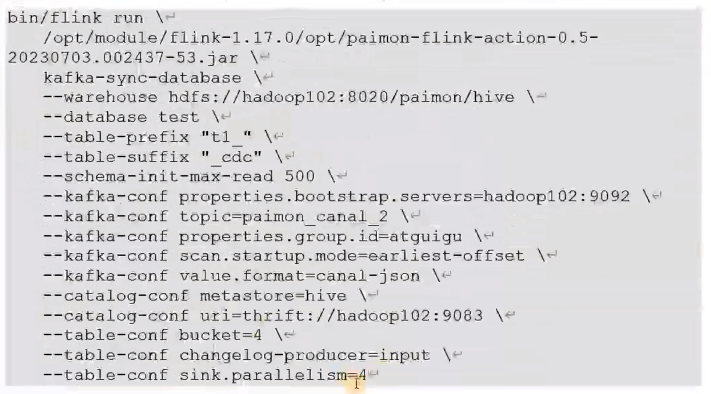
支持schema变更
cdc集成支持有限的schema变更,目前框架无法删除列,因此DROP的行为将被忽略,RENAME将添加新列
当前支持的架构更改包括:
- 添加列
- 更改列类型
- 从字符串类型更改为长度更长的另一种字符串类型
- 从二进制类型更改为长度更长的另一种二进制类型
- 从整数类型 更改为范围更广的另一种整数类型
- 从浮点类型更改为范围更宽的浮点类型
