Blog
spark-01 spark vs hadoop
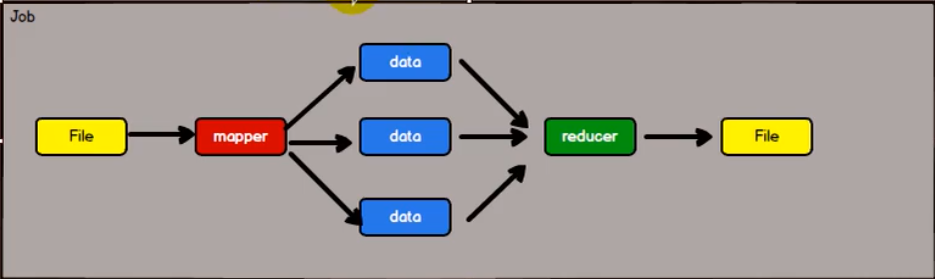
File:数据源
Mapper:将数据读取出来并打散数据
data:数据
reducer:聚合数据
最后落盘File
上一次计算结果为下一次计算使用,磁盘IO会非常影响性能
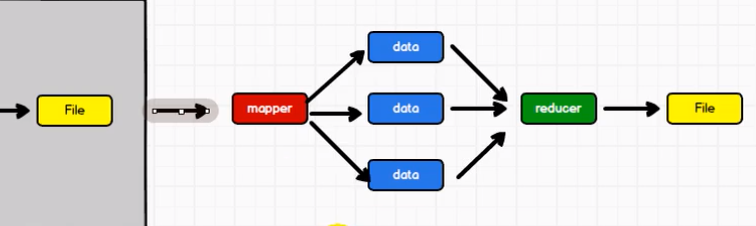
不适合循环迭代式数据流处理
Spark改进
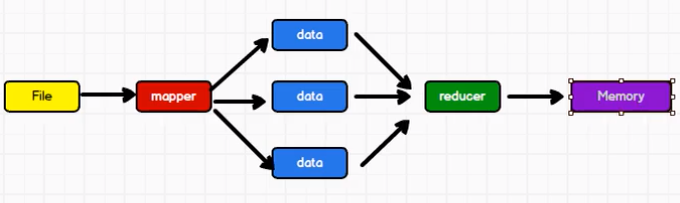
Spark将落盘计算结果放到了Memory内存中
File:数据源
Mapper:将数据读取出来并打散数据
data:数据
reducer:聚合数据
最后落盘File
上一次计算结果为下一次计算使用,磁盘IO会非常影响性能
不适合循环迭代式数据流处理
Spark改进
Spark将落盘计算结果放到了Memory内存中