Blog
zookeeper-03 zookeeper内部原理
选举机制
- 半数机制:集群中半数以上机器存活,集群可用。所以zookeeper适合安装奇数台服务器
- zookeeper虽然在配置文件中并没有指定leader和follower,但是zookeeper工作时,是有一个节点为leader,其他节点为follower,Leader是通过内部的选举机制临时产生的
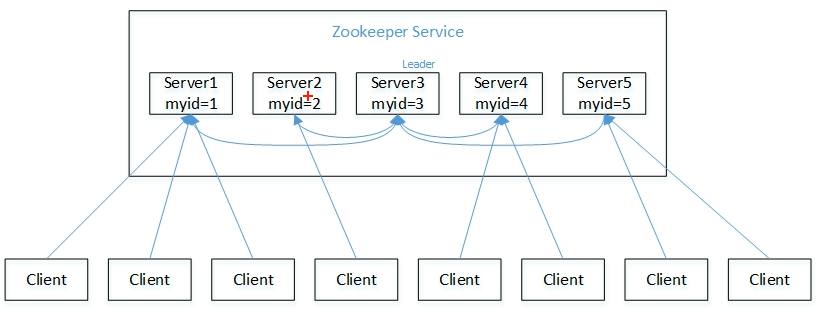
server逐个启动,启动后每个server都是先选自己,选自己不行了,再选择id最大的
- server1启动
- 选自己为leader
- 只启动一台,选举状态为LOOKING,所以不行
- server2启动
- 选自己为leader
- server1 选择id最大的 2
- server2 两票 没到半数 所以不行
- server3启动
- 选自己为leader
- server1、server2 选id最大的3
- 超过半数 3 票,成为leader
节点类型
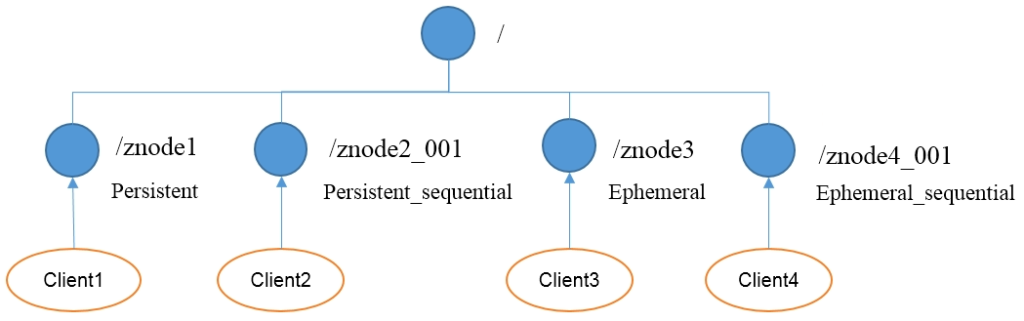
持久型:客户端和zookeeper断开连接后,创建的节点不删除
- 持久化目录节点
- 持久化顺序编号目录节点
- zookeeper给节点名称进行顺序编号
- 创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
- 在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序(先添加的哪个服务器)
短暂型:客户端和zookeeper断开连接后,创建的节点自己删除
- 临时目录节点
- 临时顺序编号目录节点
Stat结构体
cZxid = 0x1500000009
ctime = Wed Mar 10 16:05:42 CST 2021
mZxid = 0x1500000009
mtime = Wed Mar 10 16:05:42 CST 2021
pZxid = 0x1500000009
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x300004622880000
dataLength = 0
numChildren = 0- czxid 创建节点的事务zxid
- 每次修改zookeeper状态都会收到一个zxid形式的时间戳,也就是zookeeper事务id,事务id是zookeeper中所有修改总的次序,每个修改都有唯一的zxid
- 如果zxid1小于zxid2,那么zxid1在zxid2之前发生
- ctime 被创建的时间
- mzxid 最后更新的事务zxid
- mtime最后修改的时间
- pZxid 最后更新的子节点zxid
- cversion 子节点变化号
- dataversion 数据变化号
- aclVersion 访问控制列表的变化号
- ephemeralOwner 如果是历史节点 这个是znode拥有者的session id,如果不是临时节点则是0
- dataLength 数据的长度
- numChildren 子节点的数量
监听器原理

- 首先要有一个main线程
- 在main线程中创建zookeeper客户端,这时就会创建两个线程,一个负责网络连接通信connect,一个负责监听listener
- 通过connect线程将注册的监听事件发送给zookeeper
- 在zookeeper的注册监听器列表中将注册监听事件添加到列表中
- zookeeper监听到有数据或路径变化 就会将这个消息发送给listener线程
- listener线程内部调用了process方法
- 常见的监听
- 监听节点数据的变化
- get path [watch]
- 监听子节点增减的变化
- ls path [watch]
- 监听节点数据的变化
写数据流程
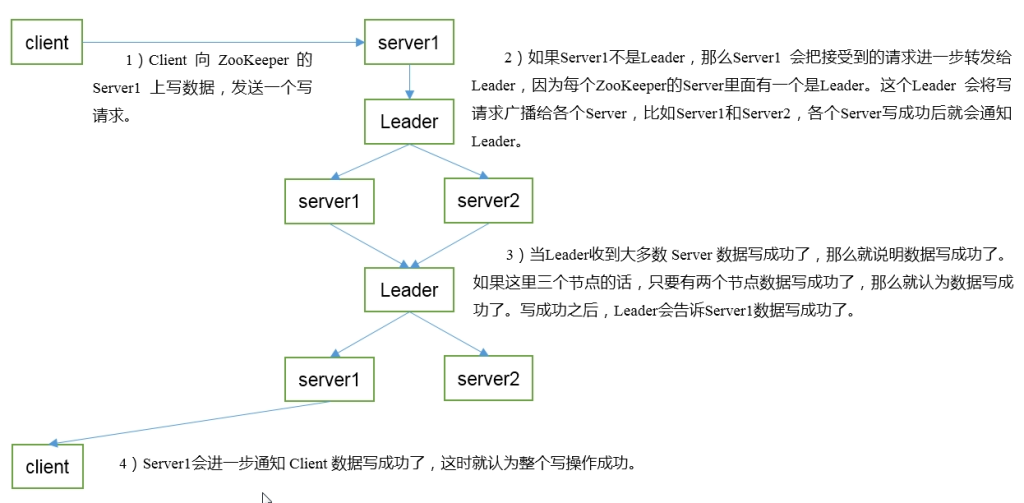
- client向zookeeper的server1上写数据,发送一个请求
- 如果server1不是leader,那么server1会把接收到的请求转发给leader,这个leader会将请求广播发给每个server,各个server写成功后就会通知leader
- 当leader收到大多数server数据写成功了,那么就认为数据写成功了,leader会告诉server1数据写成功了
- server1会进一步通知client数据写成功了