Blog
flink-31 容错机制
在flink中有一套完整的容错机制来保证故障后的恢复,其中最重要的就是检查点
检查点
在流处理中可以用存档读档的思路,将之前某个时间点所有的状态保存下来,这份存档就是所谓的检查点(checkpoint)
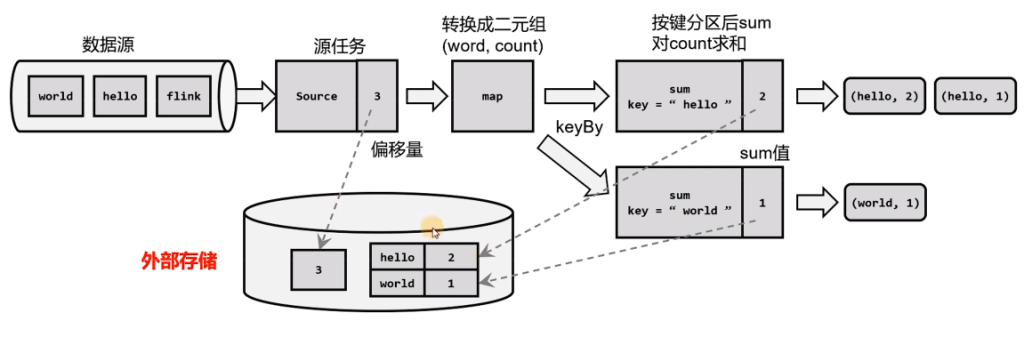
遇到故障重启的时候,我们可以从检查点中读档,恢复出之前的状态,这样就可以回到当时保存的一刻接着处理数据了。
这里所谓的检查,其实是对故障恢复的结果而言的:故障恢复之后继续处理的结果,应该与发生故障前完全一致,我们需要检查结果的正确性,所以,有时又把checkpoint叫做一致性检查点。
检查点的保存
(1)周期性的触发保存
在flink中检查点的保存时周期性触发的,间隔时间可以进行设置
(2)保存的时间点
我们应该在所有任务(算子)都恰好处理完一个相同输入数据的时候,将他们的状态保存下来,这样做可以实现一个数据被所有任务(算子)完整地处理完,状态得到了保存。
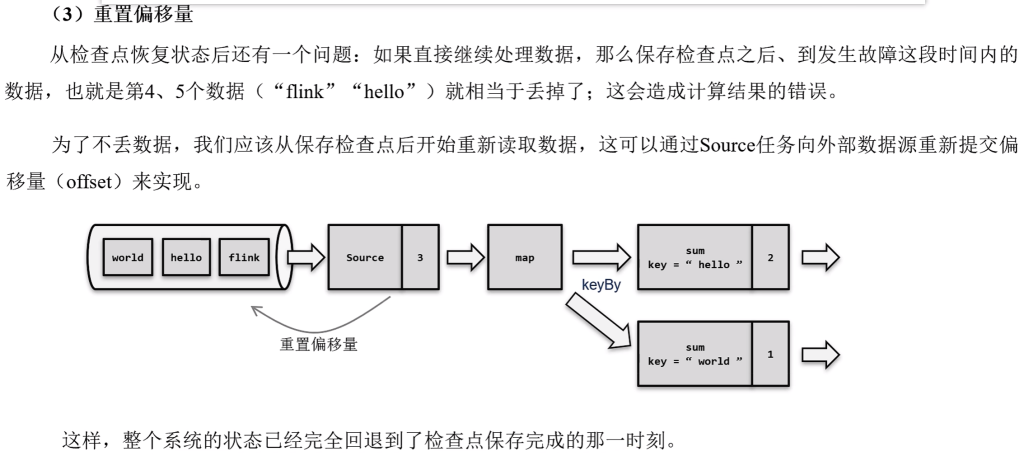
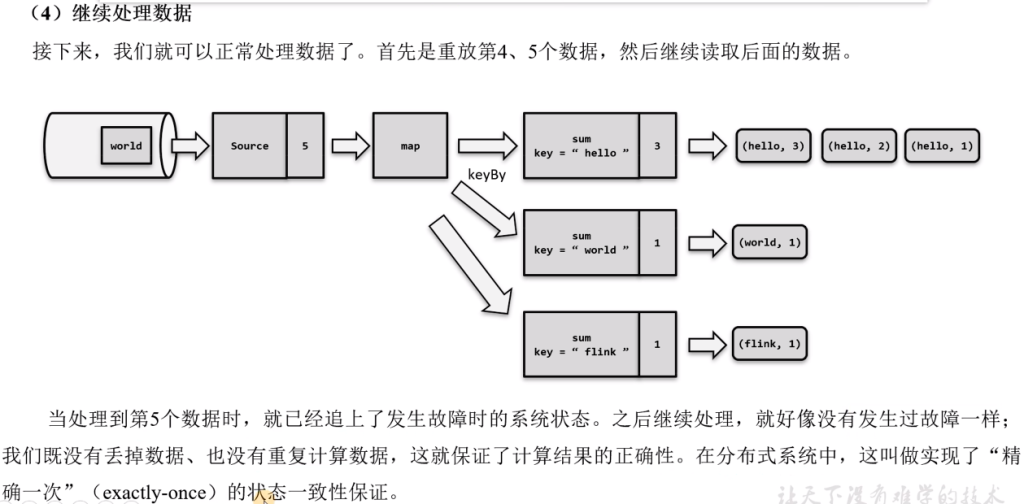
如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理:我们只需要让源(source)任务向数据源重新提交偏移量、请求重发放数据就可以了。
- 这需要原任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量
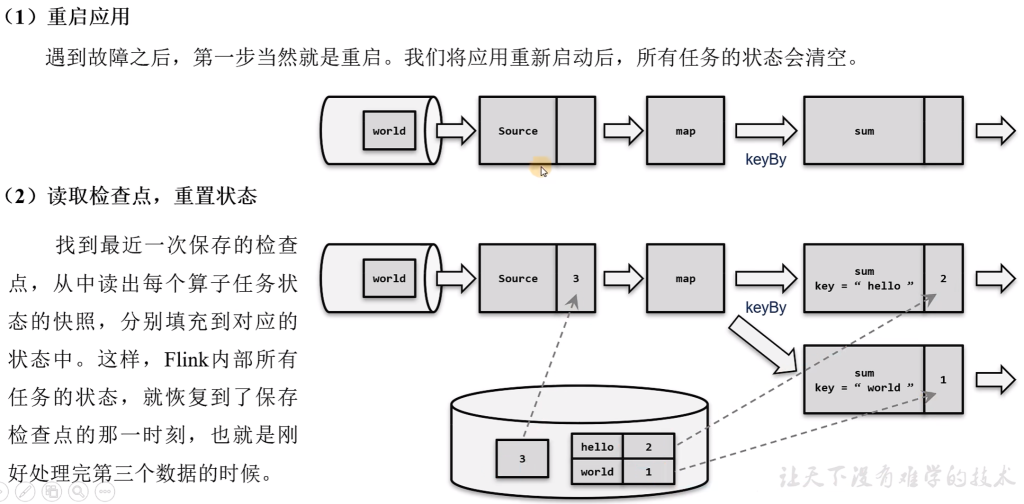
从检查点恢复状态
当发生故障时,就需要找到最近一次成功保存的检查点来恢复状态。
检查点算法
检查点分界线(Barrier)
在flink中采用了基于Chandy-Lamport算法的分布式快照,可以在不暂停整体流处理的前提下,将状态备份保存到检查点。
把一条流上的数据按照不同的检查点分隔开,叫做检查点分界线(Checkpoint Barrier)
JobManager发送指令开始备份,在所有source中生成barrier,并且barrier中保存编号(标识第几轮的checkpoint),barrier随数据流向下游进行
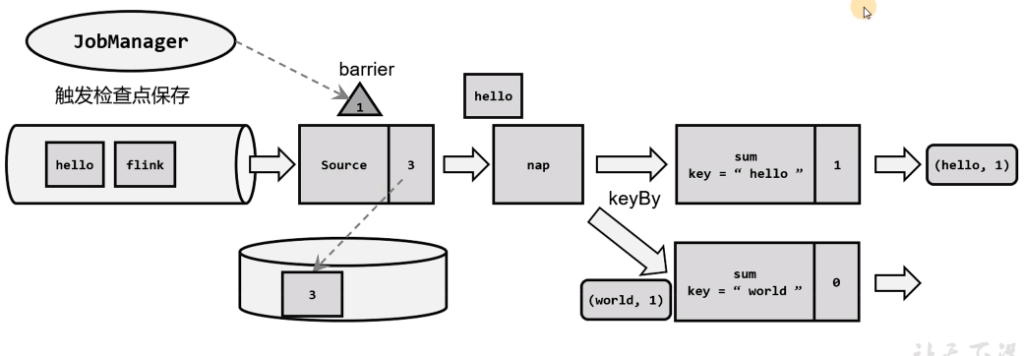
JobManager中有一个检查点协调器,专门用来协调处理检查点相关工作。检查点协调器会定期向TaskManager发送指令,要求保存检查点(带着检查点ID)TaskManager会让所有的Source任务把自己的偏移量(算子状态)保存起来,并将带有检查点ID分界线插入到当前数据流中,然后像正常的数据一样向下游传递,之后source任务就可以继续传入新的数据了
检查点算法的总结
1、Barrier对齐:一个Task收到所有上游 同一个编号的barrier之后,才会对自己的本地状态做备份
- 精准一次:在barrier对齐过程中,barrier后面的数据阻塞等待(不会越过barrier)
- 至少一次:在barrier对齐过程中,先到的barrier,其后面的数据 不阻塞 接着计算
2、非barrier对齐,一个task收到第一个barrier时,就开始执行备份,能保证精准一次(flink1.11出的新算法)
- 先到的barrier将本地状态备份,其后面的数据接着计算输出
- 未到的barrier将其前面的数据接着计算输出,同时也保存到备份中
- 最后一个barrier到达 该Task时,这个Task的备份结束